the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 02 Jun 2022
| 02 Jun 2022
GeoAI: a review of artificial intelligence approaches for the interpretation of complex geomatics data
Roberto Pierdicca
Marina Paolanti
Researchers have explored the benefits and applications of modern artificial intelligence (AI) algorithms in different scenarios. For the processing of geomatics data, AI offers overwhelming opportunities. Fundamental questions include how AI can be specifically applied to or must be specifically created for geomatics data. This change is also having a significant impact on geospatial data. The integration of AI approaches in geomatics has developed into the concept of geospatial artificial intelligence (GeoAI), which is a new paradigm for geographic knowledge discovery and beyond. However, little systematic work currently exists on how researchers have applied AI for geospatial domains. Hence, this contribution outlines AI-based techniques for analysing and interpreting complex geomatics data. Our analysis has covered several gaps, for instance defining relationships between AI-based approaches and geomatics data. First, technologies and tools used for data acquisition are outlined, with a particular focus on red–green–blue (RGB) images, thermal images, 3D point clouds, trajectories, and hyperspectral–multispectral images. Then, how AI approaches have been exploited for the interpretation of geomatic data is explained. Finally, a broad set of examples of applications is given, together with the specific method applied. Limitations point towards unexplored areas for future investigations, serving as useful guidelines for future research directions.





Geomatics is a discipline that deals with the automated processing and management of complex 2D or 3D information. It is defined as a multidisciplinary, systemic, and integrated approach that allows collecting, storing, integrating, modelling, and analysing spatially georeferenced data from several sources, with well-defined accuracy characteristics and continuity, in a digital format (Gomarasca, 2010).
Nowadays, the processing of large amounts of data and information in an interdisciplinary and interoperable way relies on a growing variety of tools and data collection methods. The binomial science and technology directly connected to the geomatics disciplines allow the continuous development of techniques for acquiring and representing data. Surveying and representation are closely linked to each other, as shown by the close connection between the disciplines traditionally associated with surveying, such as geodesy, topography, photogrammetry, and remote sensing, and those related to representation, such as cartography (Konecny, 2002).
Geomatics data are acquired by various systems and platforms, generating geospatial and spatiotemporal heterogeneous information; indeed, the acquisition techniques provide different geomatics data, which can be images (RGB, multispectral and hyperspectral as well as thermal), trajectories, and point clouds. To date, existing algorithms for data processing mainly work with manual or semiautomatic approaches, since full automation has not yet achieved greater reliability and accuracy. The resulting metric and georeferenced information are then used, catalogued, administered, displayed, and stored in a geographic information system (GIS) or generic databases. However, after moving into the era of big data, the analysis and practical use of the information contained within this huge amount of data require tailored computational approaches such as machine learning (ML) and deep learning (DL) (LeCun et al., 2015). The attractive feature of AI is its ability to identify relevant patterns within complex, nonlinear data without the need for any a priori mechanistic understanding of the geomatics processes. Today, DL and AI algorithms have been successfully developed and applied in many geomatics applications (Martín-Jiménez et al., 2018; Zhang et al., 2020). According to the type of data collected, different AI methods are proposed for classification, semantic segmentation, or object detection (Hong et al., 2020b).
1.1 Theoretical background, motivation, and research questions
Existing reviews explore particular geomatics data approaches, generally based on ML and DL, to solve a specific issue. Examples of well-structured systematic reviews focused on RGB-D images (Guo et al., 2016; Y. Li et al., 2018; Zhao et al., 2019; Zhu et al., 2017), thermal images (Ali et al., 2020; Dunderdale et al., 2020; Kirimtat and Krejcar, 2018; Vicnesh et al., 2020), point clouds (Guo et al., 2020; Y. Li et al., 2020; Xie et al., 2020; J. Zhang et al., 2019), trajectories (Bian et al., 2018; Yang et al., 2018a; Bian et al., 2019), and hyperspectral and multispectral images (Audebert et al., 2019; Ghamisi et al., 2017; S. Li et al., 2019; Signoroni et al., 2019; Yuan et al., 2021; Zang et al., 2021; Kattenborn et al., 2021) as well as their applications are available in the scientific literature. However, while the scientific literature recognises the importance of geomatics data processing since it covers many fields of application, there is a lack of systematic investigation dealing with AI-based data processing techniques. For geospatial domains, fundamental questions include how AI can be specifically applied to or must be specifically created for geospatial data. (Janowicz et al., 2020) proposed an overview of spatially explicit AI. ML has been a core component of spatial analysis in geomatics for classification, clustering, and prediction. In addition, DL is being integrated with geospatial data to automatically extract useful information from satellite, aerial, or drone imagery (just to mention some) by means of image classification, object detection, semantic, and instance segmentation. The integration of AI, ML, and DL with geomatics is broadly recognised and defined as “geomatics artificial intelligence” (GeoAI).
Considering the latest achievements in data collection and processing (Grilli et al., 2017), geomatics is facing the worldwide challenge of, on one hand, reducing the need for manual intervention for huge datasets and, on the other, improving methods for facilitating their interpretation. GeoAI could represent the turning point for the entire research community, but, to the best of our knowledge, there is currently no survey on this emerging topic.
To close this gap, this review aims to provide a technical overview of the advances and opportunities offered by AI for automatically processing and analysing geomatics data. This work emphasises that, despite their specific technical requirements, the computational methods used for these tasks can be integrated within a single workflow to optimise several steps of interpreting complex geomatics data, regardless of the application. Considering the multidisciplinary nature of geomatics data, major efforts have been undertaken in regard to RGB-D images, infrared thermographic (IRT) images, point clouds, trajectory data (TRAJ), and multispectral imaging (MSI) and hyperspectral imaging (HSI). Initially, a literature review was conducted to understand the main data acquisition technologies and if and how AI methods and techniques could help in this field. In the following account, specific attention is given to the state of the art in AI with the selected data type mentioned above. In particular, the techniques and methods for each type of research are analysed, the main paths that most approaches follow are also summarised, and their contributions are indicated. Thereafter, the reviewed approaches are categorised and compared from multiple perspectives, including methodologies, functions, and an analysis of the pros and cons of each category. Each technology and method reported in Fig. 1 will be analysed.
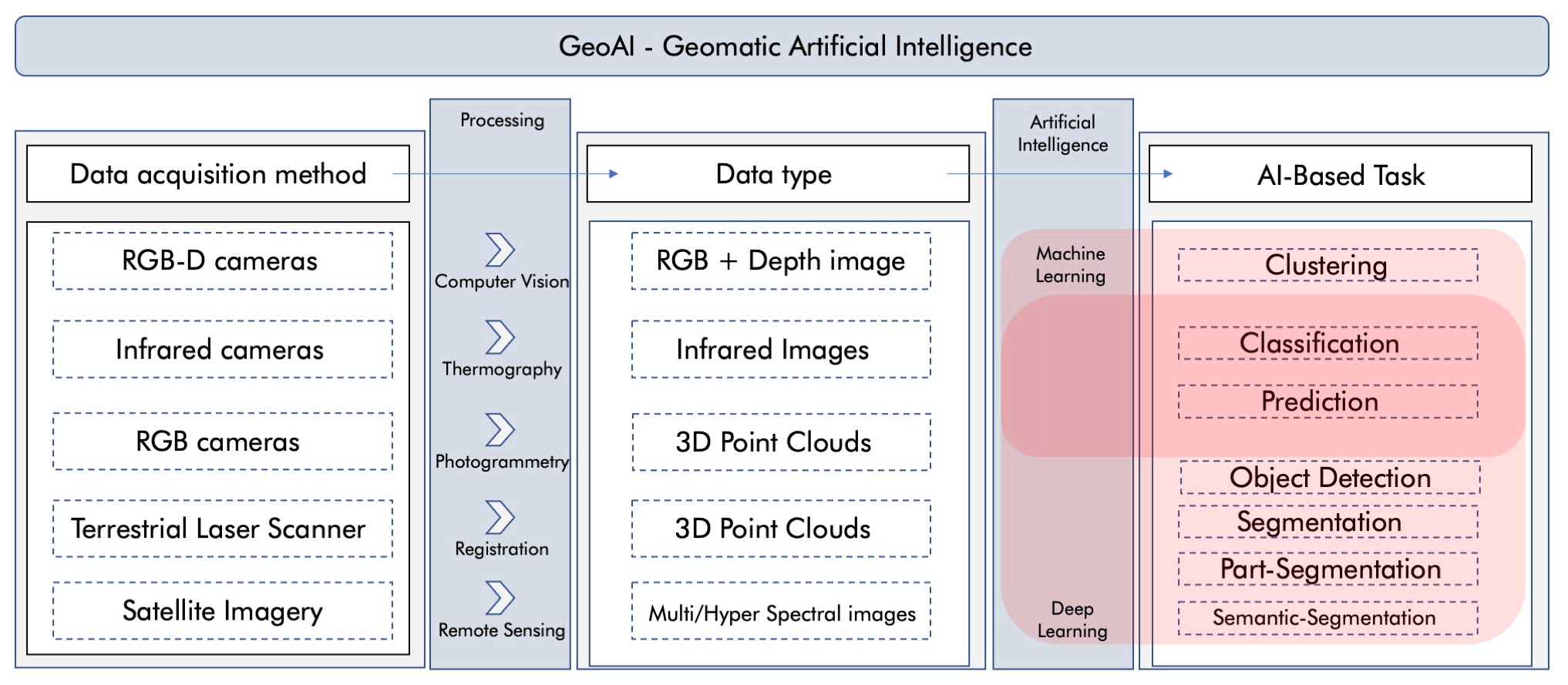
Figure 1Artificial intelligence approaches for the interpretation of complex geomatics data. Conceptualisation of the review process.
In particular, the purposes, issues, and motivations of this study were investigated to set the following research questions (RQs).
- RQ1
To explore the most commonly used methodologies in recent years for dealing with geomatics data, the following question has been set: among the well-established AI methods, which is the most commonly used in geomatics?
- RQ2
To understand if the methodologies used depend on the processed data, the following question arises: do geomatics data influence the choice of using one methodology rather than another?
- RQ3
To provide an overview of the main tasks performed using geomatics data, the following question must be answered: for which tasks are geomatics data used?
- RQ4
To better understand which type of geomatic data is used in different application domains, the following question arises: are there relationships between application domains and geomatics data?
1.2 Paper organisation
To enhance its readability and facilitate reader comprehension, the paper has been structured as follows. Section 1.3 describes the methodology adopted in the choice of the articles identified and selected for the review work. Section 2 presents the related work on the application of AI methods to the geomatics data in the test. Section 3 summarises the concepts, existing techniques, and important applications of GeoAI. Section 4 describes the limitations and implications of this research, highlighting some emerging applications of AI for geomatics data analysis. Finally, Sect. 5 presents the implications of the research and concluding remarks.
1.3 Research strategy definition
A systematic review of the literature was conducted using PRISMA guidelines and electronic databases: ieeeXplore1, Scopus2, Sciencedirect3, citepseerx4, and SpringerLink5. A set of keywords was chosen in relation to the remote sensing domain and based on preliminary screening of the research field. The keywords considered in the research initially were as follows: geomatics data, pattern recognition, artificial intelligence, machine learning, neural networks, supervised learning, unsupervised learning, statistical methods, active learning, imbalanced class learning, deep learning, convolutional neural networks, classification, segmentation, detection, pattern recognition, applications, remote sensing data, hyperspectral data, point clouds data, RGB-D data, thermal data, and trajectory.
To obtain more accurate results, the keywords were aggregated. In a set of queries, the keyword geomatics data was combined with others related to the methodologies (ML, DL, and more), and in other sets, remote sensing data were combined with the application (classification or detection). Each query produced a large quantity of articles, which were selected based on their pertinence and year of publication. Articles considered inconsistent with the research topic and published before the year 2016 were removed from the list.
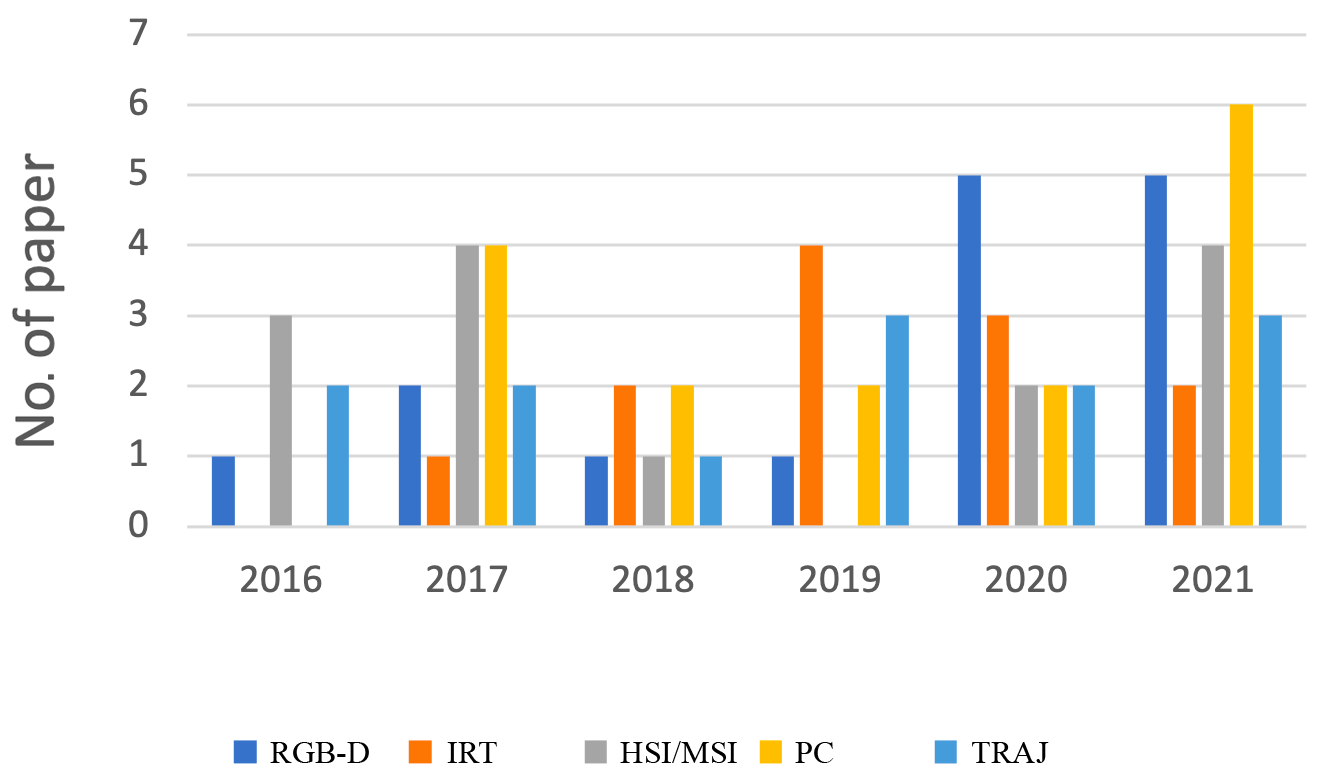
The temporal distribution of works dealing with geomatics data is shown in Figs. 2 and 3. The papers considered for the review were published between the years 2016 and 2021. Figure 2 shows the temporal distribution of works dealing with AI for geomatics data. Figure 3 highlights the number of papers taken into consideration divided by the year of publication and by the type of geomatics data.
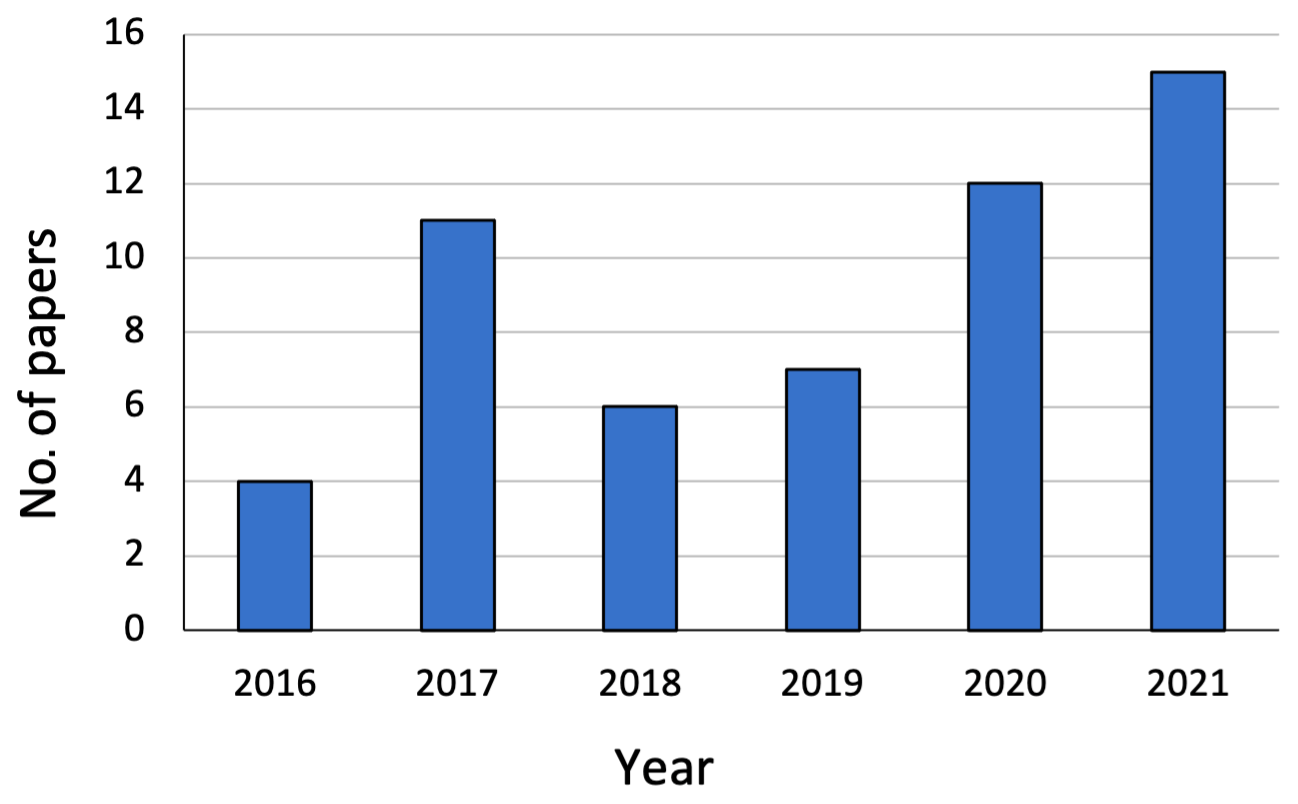
This section provides more detail on the articles in which AI algorithms are applied for the management, processing, and interpretation of geomatics data. A set of keywords was used to perform the search phase on the channels listed in Sect. 1.3 and according to the taxonomy designed in Fig. 1. Starting from a brief description of AI algorithms and models, a list of articles was collected respecting the stop criterion described in the search strategy definition. The study aims to classify research published in the field of ML and DL related to several aspects in order to compare these methods and identify their advantages and disadvantages in the application analysis.
2.1 Algorithms and models for GeoAI
AI aims to model the functioning of the human brain and, based on the knowledge acquired, create more advanced algorithms. Data analysis has changed significantly with the emergence of AI and its subsets ML and DL (Paolanti and Frontoni, 2020). Over the past years, ML and feature-based tools were developed with the aim of learning relevant abstractions from data. Nonetheless, after moving into the era of multimedia big data, ML approaches have matured into DL approaches, which are more efficient and powerful to deal with the huge amounts of data generated from modern approaches and cope with the complexities of analysing and interpreting geomatics data. DL has taken key features of the ML model and has even taken it one step further by constantly teaching itself new abilities and adjusting existing ones (LeCun et al., 2015). The most cited definition of ML is by Mitchell: “It is said that a program learns from experience E with reference to certain classes of tasks T and with performance measurement P, if its performance in task T, as measured by P, they improve with experience E” (Mitchell, 1997). In other words, an ML model constantly learns through experience and the rules are not established previously by the programmer, who defines only the features of interest, and then the machine learns by analysing the available data and achieves the results autonomously by making generalisations, classifications, and reformulations. Compared to a traditional approach that consists of identifying a specific function according to which a specific input will always produce a certain output, in the ML generic mathematical and statistical algorithms are used, which, after receiving a series of data through a training phase followed by the evaluation of the results and the optimisation of the parameters, determine the function independently.
DL (Yan et al., 2015; Goodfellow et al., 2016) is a subset of ML that is able to provide high-level abstraction models for a wide range of nonlinear phenomena. The purpose of DL algorithms is to replicate the functioning of the human brain by understanding the path that information takes inside and the way it interprets images and natural language. Therefore, DL architectures have found great application in image classification. In this application we can see the biggest differences between ML and DL. In fact, an ML workflow is started with the manual extraction of significant features from images, so the extracted features allow the creation of a model to categorise objects in the image. Unlike in DL, the feature extraction from images is automatically done and an end-to-end learning is performed in which a network independently learns how to process data and perform an activity. These techniques have resulted in important advances in various disciplines, such as computer vision, natural language processing, facial and speech recognition, and signal analysis in general. DL relies on different models to represent objects. An image, for example, can be processed as a simple vector of numerical samples or with other types of representations. Numerous DL techniques are influenced by neuroscience and are inspired by information processing and communication models of the nervous system, considering the way in which connections are established between neurons based on received messages, neuronal responses, and the characteristics of the connections themselves. DL methods are also able to replace some particularly complex artefacts with algorithmic models of supervised or unsupervised learning through hierarchical characteristic extraction techniques. In fact, they use multiple layers to extract and transform features. Each layer receives the weighted output of a neuron of the previous level. It is therefore possible to switch from the use of low-level parameters to high-level parameters, with the different levels corresponding to different levels of data abstraction. In this way, it is possible to get closer to the semantic meaning of the data and to give them the form of images, sounds, or texts. Several DL architectures, such as deep neural networks, convolutional neural networks, and recurrent neural networks, have been applied to the computer vision, automatic speech recognition, natural language processing, audio recognition, and bioinformatics fields, yielding better performance than ML algorithms in many computer vision tasks (Ongsulee, 2017).
In general, AI-based algorithms, especially deep neural networks (DNNs), are transforming the way of approaching real-world tasks done by humans. Despite applications to problems in geosciences being in their infancy, across the key problems (classification, anomaly detection, regression, space- or time-dependent state prediction) there are promising examples (Zhang et al., 2016; Ball et al., 2017). DNN architectures are increasingly being adopted in geomatics due to their competence to learn relevant abstractions from data. At first, these models were considered “black box” operators, but as their popularity has grown they need to be interpretable and explainable (Xiao et al., 2018; Elhamdadi et al., 2021; Fuhrman et al., 2021). Moreover, deep learning methods are needed to cope with complex statistics, multiple outputs, different noise sources, and high-dimensional spaces. New network topologies that exploit not only local neighbourhood but also long-range relationships are urgently needed, but the exact cause-and-effect relations between variables are not clear in advance and need to be discovered. And more, deep learning models can fit observations very well, but predictions may be physically inconsistent or implausible owing to extrapolation or observational biases. Integration of domain knowledge and achievement of physical consistency by training models about the governing physical rules of geomatics data can provide very strong theoretical constraints on top of the observational ones (Greco et al., 2020).
The main geomatics tasks solved with ML and DL models can be summarised as follows:
-
clustering (Shi and Pun-Cheng, 2019);
-
object detection (K. Li et al., 2020);
-
segmentation (Minaee et al., 2021);
-
part segmentation (Adegun et al., 2018);
-
semantic segmentation (Yuan et al., 2021).
The motivations behind the growing interest by the geoscientific community are numerous. The combination of unprecedented data sources, increased computational power, and recent advances in statistical modelling and machine learning offers exciting new opportunities for expanding our knowledge (Mehonic and Kenyon, 2022; Reichstein et al., 2019).
Clustering is a process of grouping homogeneous elements, based on some characteristics, in a dataset. This operation in everyday life has an unlimited number of applications and is put into practice every time any grouping is carried out (Boongoen and Iam-On, 2018).
The various clustering methods include the following.
-
The first is a connection method, such as linkage, which is a hierarchical method suitable for grouping both variables and observations (single linkage based on the minimum distance, complete linkage based on maximum distance, and average linkage based on average distance).
-
The second is a k-means method, which is a non-hierarchical and vector quantisation method that partitions n observations into k clusters, in which each observation belongs to the cluster with the nearest mean (cluster centres), working as a prototype of the cluster.
-
The last is a spectral cluster, which is an approach with origins in graph theory wherein the method is used to classify communities of nodes in a graph based on the edges connecting them. The process is adaptable and allows clustering non-graph data.
Classification is the process of learning a certain target function f, which maps an input vector x to one of the predefined labels y. The target function is also referred to as the classification model (Tan et al., 2016).
A classification model generated through a learning algorithm must be able to adapt correctly to the input data but also, and more importantly, to correctly predict record class labels that it has never seen before. That is, the key objective of the learning algorithm is to build models with good generalisation skills.
Object detection is an important problem that consists of identifying instances of objects within an image and classifying them as belonging to a certain class (e.g. humans, animals, or cars) (K. Li et al., 2020). The goal is to develop computational techniques and models that provide one of the basic elements necessary for computer vision applications, specifically knowing which objects are in an image. Object detection is the basis of many applications for computer vision, such as instance segmentation, image captioning, and object tracking. From an application point of view, it is possible to group object detection into two categories: “general object detection” and “detection applications” (Liu et al., 2020). For the first, the goal is to investigate methods for identifying different types of objects using a single framework to simulate human vision and cognition. In the second case, we refer to the recognition of objects of a certain class under specific application scenarios: this is the case of applications for pedestrian detection, face detection, or text detection. Currently, the models for object detection can be divided into two macro-categories: two-stage and one-stage detectors. Two-stage models divide the task of identifying objects into several phases, following a “coarse-to-fine” policy. One-stage models complete the recognition process in a single step with the use of a single network.
The problem of image segmentation is a topical research field due to its numerous applications in different fields, from signal processing at the industrial level to the biomedical sector, where it can represent a valid technique for facilitating the reading and quantitative evaluation of the outputs coming from complex diagnostic tools (e.g. magnetic resonance imaging) (Fu and Mui, 1981). Segmentation is the process that divides an image into separate portions (segments) that are groupings of neighbouring pixels that have similar characteristics, such as brightness, colour, and texture. The purpose of segmentation is to automatically extract all the objects of interest contained in an image; it is a complex problem due to the difficult management of the multitude of semantic contents (Sultana et al., 2020).
According to Naha et al. (2020), several recent papers have demonstrated that the use of DL approaches yields very good performance on object part segmentation considering both rigid and non-rigid objects.
As mentioned earlier, an image segmentation model enables partitioning an image into different regions representing the different objects. We talk about semantic segmentation when the model is also able to establish the class for each of the identified regions. In other words, carrying out a semantic segmentation means dividing an image into different sets of pixels that must be appropriately labelled and classified in a specific class of belonging (e.g. animals, humans, buildings).
Semantic segmentation can be a useful alternative to object detection, as it allows the object of interest to cover multiple areas of the image at the pixel level. This technique detects irregularly shaped objects, unlike object detection, whereby objects must fit into a bounding box (Felicetti et al., 2021).
Semantic segmentation of point clouds is also an important step for understanding 3D scenes. For this reason, it has received increasing attention in recent years and a lot of AI approaches have been proposed to automatically identify objects (J. Zhang et al., 2019; Malinverni et al., 2019; Paolanti et al., 2019).
2.2 Geomatics: a fundamental source of data
This section aims to classify the various types of sensors for data acquisition and describe their characteristics. The classification scheme was selected according to the acquisition device and data features, considering the following: (i) the output data structuring, (ii) the active–passive sensors, and (iii) the type of actuation. The main distinction in this review is the type of sensor (i.e. if the acquisition system is supplied with a laser sensor or on a vision sensor, such as a camera). It is fair to state that this is not an exhaustive list of all possible geomatic techniques; rather, it attempts to embrace all the sensors that generate data for which interpretation, given their complexity, requires the aid of statistical learning-based approaches.
A revolutionary turning point in terms of the concept of geomatics was brought by the research paper titled “Geomatics and the New Cyber-Infrastructure” (Blais and Esche, 2008). In that paper, the authors state that geomatics deals with multiresolution geospatial and spatiotemporal information for all kinds of scientific, engineering, and administrative applications. This can be summarised as follows: geomatics is far more than the concept of simply measuring distances and angles. A few decades ago, surveying technology and engineering involved only distance and angle measurements and their reduction to geodetic networks for cadastral and topographical mapping applications. Surveying still plays a leading technological role, but it has evolved in new forms. Topographical mapping, once conducted with bulky instruments requiring complex computations on the part of researchers, has now become a by-product of geospatial or GIS; digital images, obtained with different sensors (from satellite images to smartphones), can be used to accomplish the tasks of both classifying the environment and making virtual reconstructions. Survey networks and photogrammetric adjustment computations have largely been replaced by more sophisticated digital processing with adaptive designs and implementations or ready-to-use equipment, such as terrestrial laser scanners (TLSs). Multiresolution geospatial data (and metadata) refer to the observations and/or measurements at multiple scalar, spectral, and temporal resolutions, such as digital imagery at various pixel sizes and spectral bands that can provide different seasonal coverage.
Analysis tasks can be performed at a regional level thanks to the use of high-resolution images from satellite or aerial images; inferring information is possible through land usage classification, and the shape can be described using ranging techniques like lidar and radar pulse. The possibilities offered by new acquisition devices for dealing with architectural-scale complex objects are numerous. Low-cost equipment (cameras, small drones, depth sensors, and so on) is capable of accomplishing reconstructions tasks. Of course, accuracy must also be considered. In fact, georeferencing complex models require more sophisticated and accurate data sources like a GNSS (Global Navigation Satellite System) receiver or TLS. In the case of small objects or artefacts, terrestrial imagery and close-range data are the best solutions for obtaining detailed information. In the following, we report the main areas of application that are closely related to geomatics, which emerged from the previous analysis: natural environment; quality of life in rural and urban environments; predicting, protecting against, and recovering from natural and human disasters; and archaeological site documentation and preservation. In sum, geomatics can cover the spectrum of almost every scale (Böhler and Heinz, 1999); while there is no panacea, the integration of all these data and techniques is the best solution for 3D surveying, positioning, and feature extraction.
2.2.1 RGB-D cameras
Before Microsoft Kinect was launched in November 2010, collecting images with a depth channel was a burdensome and expensive task. Using depth as an additional channel alongside the RGB input has the scale variance problem present in image-convolution-based approaches. In the last few years, there have been attempts to combine the increasing popularity of depth sensors and the success of learning approaches, such as ML and then DL (Chu et al., 2018; Wang et al., 2021). RGB-D cameras generate a colour representation (red, green, and blue) of a scene and allow reconstruction of a depth map of the scene itself (Han et al., 2013; Liciotti et al., 2017). The depth map is an image M of M×N dimension, in which each pixel p(x,y) represents the distance in the 3D scene of the point (x,y) from the sensor that generated it (Fu et al., 2020; Jamiruddin et al., 2018). The use of depth images compared to RGB or BW (black and white) images provides information about the third dimension and simplifies many computer vision and interaction problems, such as (i) background removal and scene segmentation, (ii) tracking of objects and people, (iii) 3D reconstruction of the environment, (iv) recognition of body poses, and (v) implementation of gesture-based interfaces (Han et al., 2013). To determine the depth map, the considered devices use a pattern projection technique. This involves a stereo vision system consisting of a projector and camera pair to define an active triangulation process.
For a semantic segmentation task involving urban–rural scenes, the work of (L. Li et al., 2017) proposes a method based on RGB-D images of traffic scenes and DL. They use a new deep fully convolutional neural network architecture based on modifying the AlexNet (Krizhevsky et al., 2012) network for semantic pixel-wise segmentation. The RGB-D dataset is built by the cityscapes dataset (Cordts et al., 2016), which comprises a large and diverse set of stereo video sequences of outdoor traffic scenes from 50 different cities. The original AlexNet is modified since they perform a batch normalisation operation on the output of each convolutional layer, and during the experimental phase, they find that this modification improves the segmentation accuracy. The modified version of AlexNet is used as the encoder network of the architecture. During the test, they evaluate the semantic segmentation performance of the proposed architecture, comparing the results obtained with RGB-D images as input and only RGB images as input. The experimental results show that the use of the disparity map increases the semantic segmentation accuracy, achieving good real-time performance.
To semantically segment RGB-D frames collected in commercial buildings and to recognise all component classes of buildings, a DL artificial neural network method is used in Czerniawski and Leite (2020). The purpose is to demonstrate that the proposed method can semantically segment RGB-D images into 13 classes of components even if the training dataset is very small. The dataset was purposely built and manually annotated using a common building taxonomy to provide complete semantic coverage. The supervised neural network used is DeepLab (Chen et al., 2017), a state-of-the-art model for semantic segmentation of images that assigns a semantic label to each pixel of the image. To demonstrate the validity of the approach, the authors compare the performance with several state-of-the-art DL methods used for building object recognition.
Finally, RGB-D images have been exploited to fulfil localisation tasks (Zhang et al., 2021) and 3D object part segmentation (Zhuang et al., 2021).
2.2.2 Infrared cameras
Thermography, or thermovision, is a non-invasive, simple, and precise investigation system that provides real-time infrared images of any object opaque to this radiation, allowing the visualisation (and quantitative representation) of its surface temperature (Gade and Moeslund, 2014). The images are usually represented in false colour scales, in which a certain colour corresponds to a certain temperature and is not the real colour of the object.
Infrared thermography (IRT) is a well-known method of examination, which is useful because it is safe, painless, non-invasive, easy to reproduce, and has low running costs. IRT combined with AI-based automated image processing can easily detect and analyse damage or other failures in images (Kandeal et al., 2021). Despite the literature proposing approaches based on single RGB data (Espinosa et al., 2020), IRT images proved to be more reliable.
The classification of defects in thermal images through an initial prevention mechanism is dealt with in the work of Ullah et al. (2017), which uses an artificial neural network architecture, specifically multi-layered perceptron (MLP), for this task. The system classifies the thermal conditions of components into two classes: “defect” and “non-defect”. They initially extract statistical first- and second-order features departing from thermal sample images. To increase the classification performance, they augment MLP with the graph cut, obtaining better performance in the identification of defects and the classification of the images.
The same application is considered in the paper of Nasiri et al. (2019), in which the authors propose a convolutional neural network architecture to automatically detect faults and monitor equipment operations of a cooling radiator. They consider infrared thermal images and a DL architecture that has the task of feature extraction and classification of six conditions of the radiator. The architecture is constructed based on a VGG-16 structure, followed by batch normalisation, dropout, and dense layers. During the experimental phase, they compare the classification performance with other traditional artificial neural networks, demonstrating high performance and accuracy in various working conditions. In the work of Ullah et al. (2020), a novel model is proposed that detects an increase in temperature in high-voltage electrical instruments to promptly intervene to avoid equipment failure that could damage the system. Any anomalies must be detected and eliminated. In this context, the authors identify faults and anomalies in IRT images using a combined DL architecture. The infrared thermal images are the input of a convolutional neural network for the feature extraction task. Then, the features vector is the input of five different ML models (RF, SVM, J48, NB, BayesNet), which are selected to categorise the performance in the classification task into defective and non-defective classes. The experimental results demonstrate that the best classifier is the RF classifier, which is the best for discriminating the binary classification.
Classification of faults in electrical equipment is considered in the work of Duan et al. (2019). They use an artificial neural network to automatically classify defects as water, oil, and air, which can reduce the performance of some materials. Through a quantitative comparison, they demonstrate that the approach that uses coefficients as features provides better performance than the one using raw data.
Finally, another interesting method is proposed by Chellamuthu and Sekaran (2019), which uses a deep neural network to classify parts of infrared images into two classes: defect and non-defect. They intend to evaluate and monitor the parts of electrical equipment to identify thermal defects at an early stage in order to promptly intervene to avoid worse damage. First, the segmented thermal images are considered. Then, based on the optimal features, the feature extraction procedure follows. The optimal feature extraction is obtained using the Opposition-based Dragonfly Algorithm (ODA). The experimental results demonstrate that the approach provides better accuracy in performance than other classification methods.
Defect detection in infrared images of photovoltaic (PV) modules is addressed in the works of Akram et al. (2020), Pierdicca et al. (2018), and Luo et al. (2019). The increase in the number of PV installations makes automatic monitoring methods important since manual and visual inspection has several limitations. In this context, these works propose a method based on a DL algorithm that can automatically identify defects in infrared images on PV modules. The main approaches used are visual geometry group-Unet (VGG-Unet) and mask region-based convolutional neural network (Mask R-CNN) architecture that simultaneously performs object detection and instance segmentation (Pierdicca et al., 2020a).
Considering the high performance in object detection achieved by YOLO (You Only Look Once) (Redmon et al., 2016), the authors in Tajwar et al. (2021) developed a tool for hotspot detection of PV modules using YOLO. Firstly, the IRT images were converted into a dataset for a classifier to detect the hotspot of PV modules. Then the learner is trained and tested with the dataset. After that, the output validates with the IRT images of PV modules. The same deep learning model choice was also adopted in Greco et al. (2020) for addressing the problem of PV panel detection.
PV module faults are also classified in the work of X. Li et al. (2018), which aims to propose a new method for automatically classifying defects in infrared thermal images.
Defect detection is the focus of the work of Gong et al. (2018), in which the authors aim to identify anomalies in electrical equipment by implementing a model based on DL. The implemented defect identification models are InceptionV2 and Inception Resnet V2. The performance of the method is also evaluated for infrared images with artificial defects.
Finally, IRT images are also used to detect faults in infrared thermal images of composite materials used in aircraft, vehicles, and several industries by exploiting their mechanical properties (Bang et al., 2020) and building monitoring (Al-Habaibeh et al., 2021).
2.2.3 Digital photogrammetry and terrestrial laser scanning
Photogrammetry is a technique that enables metrically determining the shape, size, and position of an object having two distinct photographic frames that should be central projections of the object itself (Baqersad et al., 2017). Also, 3D laser scanning technology (Lemmens, 2011) has been widely used in the engineering and construction industries. 3D laser scanners work on the principles of lidar (light detecting and ranging) by emitting a laser pulse, which hits a target and subsequently returns to the sensor (Liscio et al., 2018; Di Stefano et al., 2021).
The points captured are called a point cloud, which is then exported into laser scanning software that can create fully coloured 3D models that allow for point-to-point measurements and excellent visualisation of the scene.
The use of ML and DL techniques for point cloud classification and semantic segmentation was successfully investigated in the last decade in the geospatial environment (Weinmann et al., 2015; Qi et al., 2017a; Özdemir and Remondino, 2019). Several methods have been recently proposed (Shen et al., 2021; Xiao et al., 2021; Geng et al., 2021), and in the following a detailed review of the main approaches in the geomatics field is reported.
The pioneer DL algorithm that processes 3D point clouds is in Qi et al. (2017a). It automatically classifies and performs the semantic segmentation directly on the point clouds. They consider an architecture that first analyses the features of the single points and then identifies them globally. However, this architecture does not capture local geometries, so optimisation of this methodology is presented in Qi et al. (2017b). In this paper, to learn local features by exploiting the metric space distances, a hierarchical grouping is considered. For local neighbourhoods, the experimental phase shows improved results compared with other state-of-the-art architectures.
To handle 3D point clouds with spectral information acquired by lidar systems, the work presented by Yousefhussien et al. (2018) uses a method based on DL algorithms. They propose a modified version of PointNet (Qi et al., 2017a) to obtain a model able to operate with complex 3D data acquired from overhead remote sensing platforms using a multi-scale approach. Their DL network can directly deal with unordered and unstructured point clouds without modifying the representation and losing information. Moreover, to demonstrate the accuracy of their method, they present a performance comparison with other state-of-the-art methods. Papers like Zhang and Zhang (2017), Wang and Ji (2021), and Lee et al. (2021) make extensive use of approaches based on DL for semantic parsing of 3D point clouds of urban building scenes.
In Zhang et al. (2018), the problem of semantic segmentation of 3D scenes on a large scale is tackled by considering a fusion between 2D images and 3D point clouds. The authors create a Deeplab-Vgg16 high-resolution model (DVLSHR) based on Deeplab-Vgg16 and the Deep Visual Geometry Group (VGG16), which is successfully optimised by training seven deep convolutional neural networks on four reference datasets. The preliminary segmentation is made using 2D images, which are then mapped into 3D point clouds, taking into account the relationships among the images and the point clouds. Subsequently, based on the mapping, the physical planes of buildings are extracted from the 3D point clouds.
In the field of digital cultural heritage (DCH), the work of Pierdicca et al. (2020b) uses an improved version of DGCNN (Wang et al., 2019) that adds meaningful features, such as normal and colour. The aim is to semantically segment 3D point clouds to automatically interpret the architectural parts of buildings and obtain a useful framework for documenting monuments and sites. They use a novel dataset comprising both indoor and outdoor scenes, which are manually labelled by experts and which belong to different historical periods and styles (Matrone et al., 2020b). Extensive experiments on the purposely created dataset show the efficiency of the optimised architecture, and the results are compared with those of other state-of-the-art models. The authors have also extended the proposed approach by comparing the DL approach with an ML-based one and by the improvement of DGCNN with other relevant features (Matrone et al., 2020a).
A DL-based framework for automatically extracting, classifying, and completing road markings from three-dimensional mobile laser scanning (MLS) point clouds is presented by Wen et al. (2019). A modified version of the UNet architecture is used to extract road markings. For classification, a method based on clustering and convolutional neural networks is developed, and it is more efficient with different sizes. Finally, to complete the road marking, a method based on a conditional generative adversarial network (cGAN) is used, which is more effective since it considers the continuity and regularity of the lane lines. The dataset consists of three scenes: highways, urban roads, and underground parking, with raw point clouds and labelled road marking ground truths.
In the context of urban and rural scenes, the paper of Yang et al. (2017) proposes a method for semantically labelling 3D point clouds acquired by an airborne laser scanner using an approach based on DL. A point-based feature image generation method extracts local geometric features, global geometric features, and full-waveform features from 3D point clouds, transforming them into an image. Then, the feature images are the input of a convolutional neural network for semantic labelling. Finally, to compare the performance of the proposed approach with state-of-the-art methods, they test the framework using other publicly available datasets, achieving a high level of overall accuracy with the proposed network.
To solve a similar issue, the papers of Wang et al. (2019) and Can et al. (2021) use a novel convolutional neural network called Dynamic Graph CNN (DGCNN), which includes a new module called EdgeConv that acts on graphs dynamically computed in each layer of the network. The EdgeConv module incorporates local neighbourhood information, can be applied to learn global shape properties, and captures semantic characteristics in the original embedding. To demonstrate the performance of the proposed model, the authors use different public datasets: ModelNet40, ShapeNetPart, and S3DIS. Moreover, they compare the results with other models based on DL, obtaining better results in terms of accuracy.
To minimise the large number of point clouds needed to classify urban objects, a solution is proposed by Balado et al. (2020). The problem that they intend to address is in Balado et al. (2020). They use convolutional neural networks to convert point clouds into personal computer (PC) images, taking into account that acquiring and labelling point clouds is more expensive and time-consuming than the corresponding image. They generate several sample images per object (point clouds) using multi-view and combine PC images with images derived from online datasets: ImageNet and Google Images. The DL algorithm chosen is InceptionV3. To validate the proposed methodology, they also consider the IQmulus & TerraMobilita Contest dataset, obtaining correct classification with few samples.
Complex forest scenes represented by 3D point clouds are classified using a method based on DL in the work of Zou et al. (2017). A new voxel-based DL method classifies species of trees using 3D point clouds of forests as input and consisting of three phases: individual tree extraction, feature extraction, and classification using DL. Moreover, two different datasets acquired using terrestrial laser scanning systems are used. Then, to evaluate the performance and demonstrate the effectiveness of the proposed method, they also compare it with other classification methods for 3D tree species. Other interesting works worth mentioning in this field are Chen et al. (2021) and Pang et al. (2021).
2.2.4 Remote sensing: multispectral and hyperspectral data
Remote sensing (Toth and Jóźków, 2016) is a technical and scientific discipline that allows obtaining quantitative and qualitative information and measuring the emission, transmission, and reflection of electromagnetic radiation from surfaces and bodies placed at a long high distance from an observer. Recently, ML approaches as part of the AI domain and its DL subset have become increasingly important in MSI and HSI remote sensing analysis (Yuan et al., 2021; Zang et al., 2021). Several works have been proposed with the aim of expediting time-consuming processes (Zhu et al., 2017).
In the following, different papers are presented to solve the classification task of HSI–MSI images of urban and rural scenes, mainly using DL algorithms.
The only paper considered that uses an approach based on ML is Sharma et al. (2017). The aim is to evaluate the performance of different supervised ML classifiers in the discrimination of six vegetation physiognomic classes. They use supervised approaches with different model parameters and demonstrate that the random forests classifier provides the greatest accuracy and kappa coefficient.
The work of Zhong et al. (2017) proposes a system that classifies hyperspectral images using a supervised model based on DL. The input of the Spectral–Spatial Residual Network (SSRN) is represented by 3D raw cubes. Through identity mapping, each of the 3D convolutional layers is connected by the residual blocks. Then, to improve the classification accuracy and the learning process, a batch normalisation algorithm is used on each convolutional layer. The dataset is made up of agricultural, rural–urban, and urban hyperspectral images. The qualitative and quantitative experimental results indicate that the proposed framework achieves good classification accuracy. Many other papers adopt similar approaches, like Mendili et al. (2020) for LC–LU classification, Audebert et al. (2018) for semantic labelling, shadow detection in Movia et al. (2016), and precision farming in Zheng et al. (2020).
To deal with the hyperspectral image classification problem, Yang et al. (2018b) present a method for increasing the classification performance by exploiting both the spatial context and spectral correlation, although in general only the spatial context is considered. Specifically, they consider and evaluate the performance of four convolutional neural networks: 2DCNN, 3DCNN, recurrent 2DCNN, and recurrent 3DCNN. Six open-access datasets are used for classification. Moreover, to demonstrate that DL methods provide better performance in the classification task, four architectures are compared with other traditional methods.
In addition, Wu and Prasad (2017) propose a method for classifying hyperspectral images using DL methods. They highlight the need to have a large amount of labelled data for training, and to solve this problem they propose a semi-supervised DL approach that requires limited labelled data and a large amount of unlabelled data, which they use with their pseudo-labels (cluster labels) to pre-train a deep convolutional recurrent neural network that they fine-tune using a smaller amount of labelled data. Moreover, to use spatial information they implement a constrained Dirichlet process mixture model (C-DPMM) for semi-supervised clustering, also deriving a variational inference model.
The paper of Zhao and Du (2016) proposes a novel classification framework based on a spectral–spatial feature (SSFC) that uses dimension reduction and DL methods to extract spectral and spatial features, respectively. Spectral feature extraction is applied to high-dimensional hyperspectral images using a local discriminant algorithm, while a convolutional neural network is implemented to determine high-level spatial features. Finally, the multiple features extracted jointly considering spectral and spatial features are used to train the multiple-feature-based classifier for image classification. To demonstrate the performance of the SSFC classifier, they compare the results with those of other traditional classification methods.
A target detection for hyperspectral images using a deep convolutional neural network is proposed in W. Li et al. (2017). To train this multi-layer network, a high number of labelled samples is needed, but for target detection, few labelled targets are available. Hence, to enlarge the dataset, they further generate pixel pairs. In the experimental phase, two cases are considered: in the first, for anomaly detection, using similarity measurements, a convolutional neural network classifies different pixel pairs obtained by combining the centre pixel and its surrounding pixels; in the second, for supervised target detection, a convolutional neural network classifies different pixel pairs obtained by combining the testing pixel and the known spectral signatures.
The aim of Liu et al. (2016) is the classification of hyperspectral images using active DL. As obtaining well-labelled samples for remote sensing applications is very expensive, they consider weighted incremental dictionary learning. The algorithm selects samples by maximising two selection criteria: representativeness and uncertainty. Moreover, the network is actively trained to select training samples in each iteration. To validate the proposed architecture, during the experimental phase they compare the performance with other classification algorithms that use active learning.
In Chen et al. (2016), the argument concerns the classification task of hyperspectral data. The authors propose a DL approach to elaborate hyperspectral images. In particular, they combine a novel feature extraction (FE) and image classification architecture based on a deep belief network (DBN) to obtain high classification accuracy. During the experimental phase, they demonstrate that the framework provides encouraging classification results compared with other state-of-art methods. Moreover, they demonstrate the great potential of DL methods for classifying hyperspectral images, even confirmed in more recent works (Xu et al., 2021).
The paper proposed by Hong et al. (2020b) aims to demonstrate that the use of a framework based on DL, in particular a cross-modal DL framework called X-ModalNet, provides good results for classification tasks of multispectral imagery (MSI) and synthetic aperture radar (SAR) data. The architecture consists of three well-designed modules: a self-adversarial module, an interactive learning module, and a label propagation module. During the experimental phase, the authors compare the classification performance with other state-of-the-art methods, demonstrating significant improvement.
In the paper of Hong et al. (2020a), a framework based on DL is presented to classify hyperspectral data. In particular, convolutional neural networks and graph convolutional networks are used to classify hyperspectral images. The authors develop a new minibatch graph convolutional network to solve the problem of huge computational costs in large-scale remote sensing problems. The mini-graph convolutional network infers out-of-sample data without the need to retrain the networks and improves the classification performance. Since convolutional and graph convolutional networks extract different types of features, they are fused based on three strategies (additive fusion, element-wise multiplicative fusion, and concatenation fusion) to increase classification performance. The experimental results from three different datasets demonstrate that the use of mini-graph convolutional networks provides better performance than graph convolutional networks as well as combined convolutional and graph convolutional GCN models.
The work presented by Y. Li et al. (2019) is worth mentioning, which detects changing in synthetic aperture radar (SAR) images. The authors use a DL architecture, specifically a convolutional neural network trained to obtain a classifier able to distinguish modified pixels from unmodified pixels. This task is very important when disasters occur where it is difficult to obtain prior knowledge. To address this issue, they modify a supervised training process into an unsupervised learning process. Moreover, this method does not require image preprocessing and a filtering operation for SAR images. A convolutional neural network makes use of the spatial feature and neighbourhood information on pixels to learn the hierarchical features of the images and implement an end-to-end framework.
2.2.5 GNSS positioning
The GNSS (Global Navigation Satellite System) is a positioning system based on the reception of radio signals transmitted by various constellations of artificial satellites (Groves, 2015). Modern GPS receivers have achieved very low costs. The market now offers low-cost solutions for all uses, which are effective not only for satellite navigation but also for civil uses, monitoring mobile services, and territorial control. Consequently, trajectory forecasting has been a field of active research owing to its numerous real-world applications, thanks to the ever-increasing availability of GNSS data, for both pedestrians (Kothari et al., 2021) and vehicles (Siddique and Afanasyev, 2021).
The aim of the paper of Endo et al. (2016) is to address the problem of extracting the characteristics that estimate users' transport modes based on their movement trajectories. To compensate for a lack of handcrafted functionality, they propose a method that automatically extracts additional functionality using a deep neural network. A classification model is constructed in a supervised manner using both deep and handcrafted characteristics. The effectiveness of the proposed method is demonstrated through several experiments using two real datasets, comparing the accuracy with that of previous methods.
Another paper (Habtemichael and Cetin, 2016) presents a nonparametric, data-driven methodology for short-term traffic prediction based on recognising similar traffic patterns, employing an advanced K-closer algorithm. Additionally, winsorisation of neighbours is implemented to reduce the consequences of predominant candidates, and the rank exponent is applied to aggregate candidate values. The robustness of the proposed method is demonstrated by implementing it on large datasets derived from different regions and comparing the performance with advanced time series models, such as the SARIMA and Kalman filter adaptive models proposed by others. Furthermore, the effectiveness of the proposed advanced K-nearest neighbour (k-NN) algorithm is evaluated for multiple prediction stages, and its performance is also tested with data with missing values. This study provides strong evidence showing the promise of a nonparametric, data-driven method for short-term traffic prediction.
Obtaining knowledge from the GPS tracks of human actions is the topic of the work of Jiang et al. (2017). The authors present TrajectoryNet, a neural network architecture for point-based trajectory classification to infer real-world human transport modes from GPS tracks. A new representation is developed that includes the original feature space into another space, which can be recognised as a form of base expansion, to overcome the challenge of capturing the underlying latent factors in the low-dimensional and heterogeneous feature space imposed by GPS data. A classification accuracy greater than 98 % is achieved for identifying four types of transport modes, which exceeds the performance of existing models without further sensory data or prior knowledge of the location.
According to Xiao et al. (2017), transport mode identification can be used in a variety of applications, including human behaviour research, transport management, and traffic control (Yang et al., 2021). In this paper, a learning-set-based method is presented to infer hybrid modes of transport employing only GPS data. First, to distinguish between diverse modes of transport, a statistical approach is used to produce global features and extract different local features from sub-trajectories after trajectory segmentation before these features are combined in the classification step. Second, to obtain better performance, tree-based ensemble models (random forest, gradient boosting decision tree, and XGBoost) are used instead of traditional methods (K-nearest neighbour, decision tree, and support vector machines) to classify the different transport mode tools.
Correct detection in public transport modes is a fundamental task in smart transport systems according to James (2020). Hence, the aim is to utilise GPS trajectories of random lengths to produce efficient travel mode results in global and online classification scenarios. Raw GPS data are processed to calculate preliminary movement and displacement properties, which are fed into a tailored deep neural network. The results show that the approach can significantly exceed state-of-art travel mode identifications with the same dataset with little computation time. Moreover, an architecture test is performed to determine the best-performing structure for the proposed mechanism.
According to the work of Dabiri et al. (2019), recognising passenger transport modes is important for many issues in the transport field, such as travel demand analysis, transport planning, and traffic management. The paper aims to classify travellers' modes of transport based only on their GPS trajectories. First, a segmentation process is developed to classify a user's journey into GPS segments with only one mode of transport. Most researchers have suggested modality inference models based on hand-built functionality, which can be vulnerable to traffic and environmental conditions. SECA combines a convolutional–deconvolutional auto-encoder and a convolutional neural network into architecture to perform supervised and unsupervised learning simultaneously.
In another paper (Dabiri et al., 2020), the same authors consider the fact that transportation agencies are beginning to leverage the more available GPS trajectory data to support their analyses and decision-making. Although this representation of mobility data adds meaningful value to several analyses, a challenge is the lack of knowledge regarding the kinds of vehicles that produced the recorded tours, which restricts the value of the trajectory data in the transport system analysis. The paper presents a new design of GPS trajectories, which is compatible with deep learning models and also obtains vehicle movement features and road features. To this end, an open-source navigation system is also applied to obtain more detailed information on travel time and the distance between GPS coordinates. The experimental phase shows that the proposed CNN-VC model consistently outperforms both classical ML algorithms and other essential DL methods.
R. Zhang et al. (2019) consider that, although some studies on the classification of trajectories have been conducted, they require manual selection of characteristics or fail to completely consider the influence of time and space on the classification results. The features obtained are joined to provide the results of the final classification. Then, they present an approach based on the latest DenseNet image classification network structure and include the attention tool and residual learning. This model can fully extract spatial features to increase feature propagation and capture long-term dependence. The results show that the design outperforms traditional models in terms of accuracy, recall, and f1 score (the harmonic mean of precision and recall) .
Duan et al. (2018) consider the nonlinear and space–time characteristics of urban traffic data, proposing a deep hybrid neural network enhanced by a greedy algorithm for the prediction of urban traffic flow using GPS tracking of taxis. They propose a deep neural network model that combines a convolutional neural network, which extracts spatial features with long-term memory that captures temporal information, to predict the flow of urban traffic. Experimental results based on real taxi GPS trajectory data from the city of Xian show that the enhanced deep hybrid CNN-LSTM model has higher classification accuracy and requires a shorter time than traditional methods.
Finally, based on GPS data the work presented in Pierdicca et al. (2019b) shows that the case of urban parks is difficult, requiring knowledge of many variables, which are difficult to consider simultaneously. One of these variables is the set of people who use the parks. This study aims to produce a method to identify how an urban green park is used by its visitors to provide planners and managing authorities with a standardised method. A trajectory classification algorithm is implemented to understand the most common visitor trajectories by obtaining the advantages of GPS and sensor-based traces. Based on these user-generated data, the proposed data-driven approach can determine the park's mission by processing visitor trajectories while using a mobile application specifically designed for this purpose.
As mentioned previously, the use of AI in geomatics data management is not a new problem. Several studies have been conducted on this topic, and many are currently in development. Geomatics data are the core of several applications in which ML and DL have been applied.
The use of geographical and spatial information within society as well as in academic work has increased rapidly in recent decades. This also means that geomatics has started to create problems in both the academic and non-academic worlds. First, it bridges borders that have been in place for a long time. Second, geomatics, or rather the basic concepts of geomatics, are increasingly being used. Spatial analysis has proven to be important in all disciplines. We can find examples of strong GIS units in, for example, humanities (archaeology, human ecology, language studies, etc.), social science (human and economic geography, economy, economic history, etc.), and medicine (social and occupational medicine, epidemiology, etc.). Thus, geomatics are part of research in most disciplines, and many users are facing issues related to the integration of geomatics in their field. Geomatics are also used frequently in interdisciplinary settings, which leads to specific issues.
We close this paper by returning briefly to the questions raised at the beginning, which remain largely open.
Comparing ML and DL, which is the most commonly used in geomatics?
First of all, it is necessary to clarify that DL is a type of ML approach; in the following we compare DL and ML, and we distinguish approaches that use DL from those that use ML except DL.
The comparison between ML and DL methods is shown in Figs. 4 and 5. Figure 4 shows that the most commonly used method, especially in the last years, is DL, with an average rate of 80 % compared to a rate of 20 % for ML.
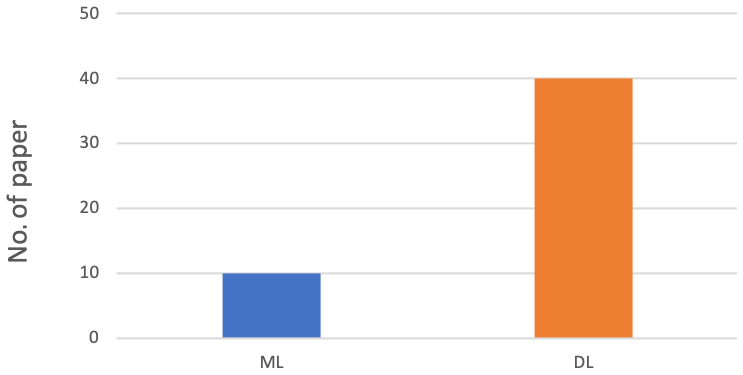

Figure 5 compares the two methodologies during the time interval considered, confirming that there is greater use of DL than ML to deal with geomatics data in the period taken into consideration.
Table 1 summarises 10 of the applications reviewed for each kind of data, comparing the input, the task, and the AI method chosen.
L. Li et al. (2017)Espinosa et al. (2020)Movia et al. (2016)Zheng et al. (2020)Czerniawski and Leite (2020)Gong et al. (2018)Duan et al. (2019)Y. Li et al. (2019)Yang et al. (2020)Wang et al. (2017)Ullah et al. (2017)Akram et al. (2020)Luo et al. (2019)Nasiri et al. (2019)Ullah et al. (2020)Gong et al. (2018)Duan et al. (2019)X. Li et al. (2018)Al-Habaibeh et al. (2021)Chellamuthu and Sekaran (2019)Wang and Ji (2021)Wen et al. (2019)Zhang et al. (2018)Zou et al. (2017)Yousefhussien et al. (2018)Yang et al. (2017)Wang et al. (2019)Pierdicca et al. (2020b)Qi et al. (2017a)Balado et al. (2020)Endo et al. (2016)Habtemichael and Cetin (2016)Jiang et al. (2017)Xiao et al. (2017)James (2020)Dabiri et al. (2019)Dabiri et al. (2020)R. Zhang et al. (2019)Duan et al. (2018)Pierdicca et al. (2019b)Sharma et al. (2017)Zhong et al. (2017)Yang et al. (2018b)Wu and Prasad (2017)Zhao and Du (2016)W. Li et al. (2017)Liu et al. (2016)Chen et al. (2016)Hong et al. (2020b)Hong et al. (2020a)Table 1Brief review of information regarding the complex geomatics data analysed in this study, which are important for selecting an appropriate AI technique.

Do geomatics data influence the choice of using one methodology rather than another?
Figure 6 shows the results in percentage terms. In the graphs, we have grouped the papers on geomatics data and the employed approach. For all data, the use of DL is gaining increasing importance, especially in point cloud semantic segmentation and classification. While for IRT data the use of DL techniques is slightly lower than the other data we considered in this work, this probably depends on the technical and physical characteristics of the IRT data. Thus, the use of one technology rather than another also depends on the type of data processed. From this analysis, it is also possible to answer RQ1, as the data demonstrate the trend in preferring DL approaches rather than ML ones.
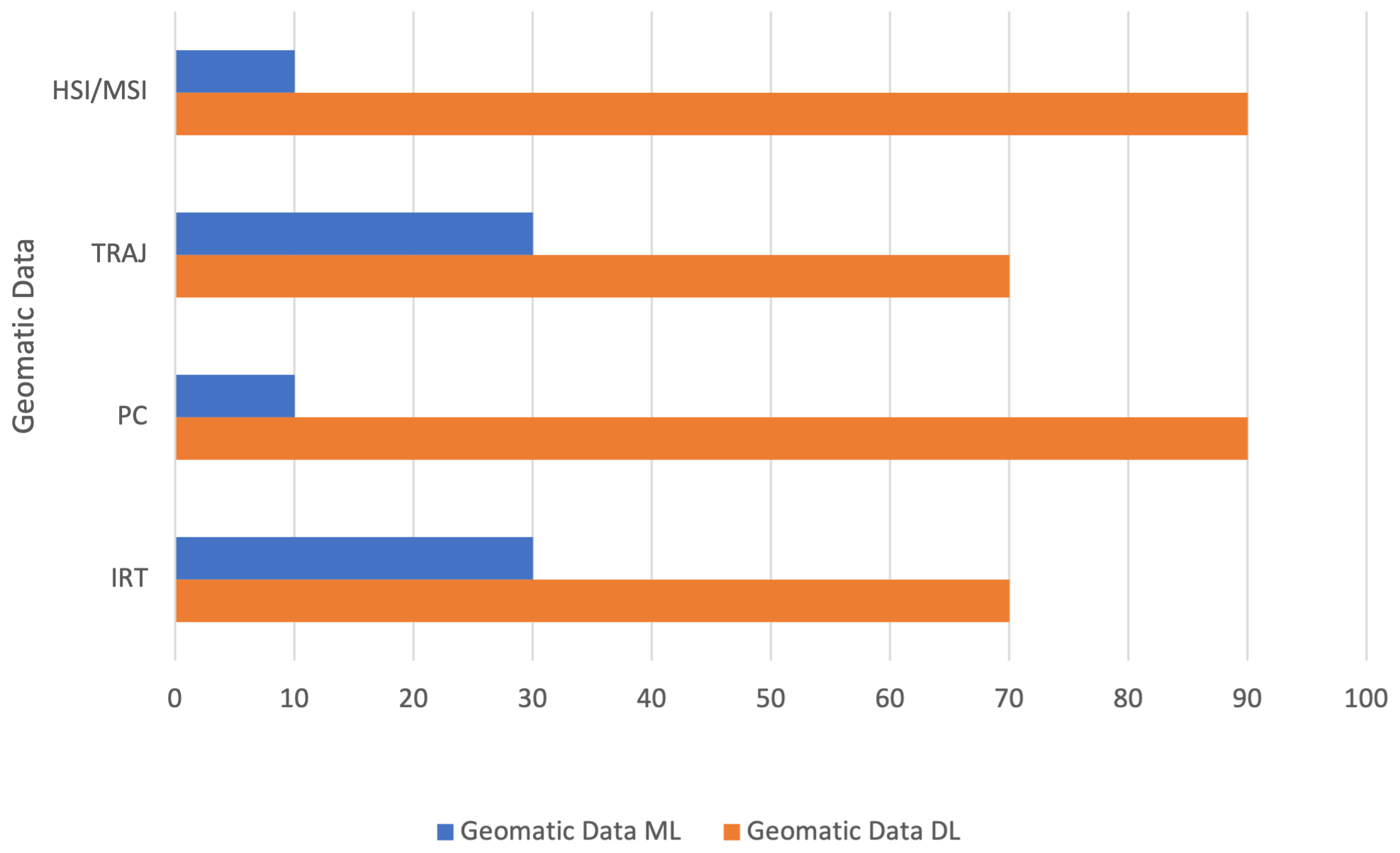
Figure 6Comparison between ML vs. DL approaches, selected according to the respective geomatics data for which they have been applied.
For which tasks are geomatics data used?
The main tasks performed using geomatics data are shown in Figs. 7 and 8. Observing Fig. 7, the classification task is the most commonly employed, with a rate of 42 %. The object detection task is employed 22 % of the time, and the semantic segmentation task has a rate of 18 %. The remaining 18 % is segmentation, part segmentation, and clustering. These results involve all geomatics data considered in this review. These data, which have different characteristics mainly due to the type of acquisition, are used in tasks that can be included in the three identified categories.


Figure 8Comparison between geomatics data and AI-based tasks. The percentage of papers follow the criteria of matching, for each kind of data, the type of AI approach used.
Figure 8 considers the task referring to all types of data. Classification is the task mostly employed with HSI and MSI data, and object detection seems to be the preferred solution when dealing with both IRT and RDB-D images. Meanwhile, the point cloud data, confirming the trend from the literature review, are mainly used for semantic segmentation (with a rate of 40 %), classification (with a rate of 30 %), and part segmentation (with a rate of 20 %) tasks. The object detection task is not executed. On the contrary, the main task for IRT data is object detection with a rate of 60 %, then classification with a rate of 30 %, and finally segmentation with a low rate (10 %). Classification and segmentation are the main tasks for the trajectory data. Other tasks are clustering and object detection with the same rate (10 %).
This analysis has been fundamental to answering RQ2. Indeed, the AI approach is strictly connected with the kind of data, thus depending on the domain in which the approach is applied (see Sect. 3).
Are there relationships between application domains and geomatics data?
Figures 9 and 10 answer RQ3 and RQ4, which seek to establish whether a relationship exists between the data type and application domains.
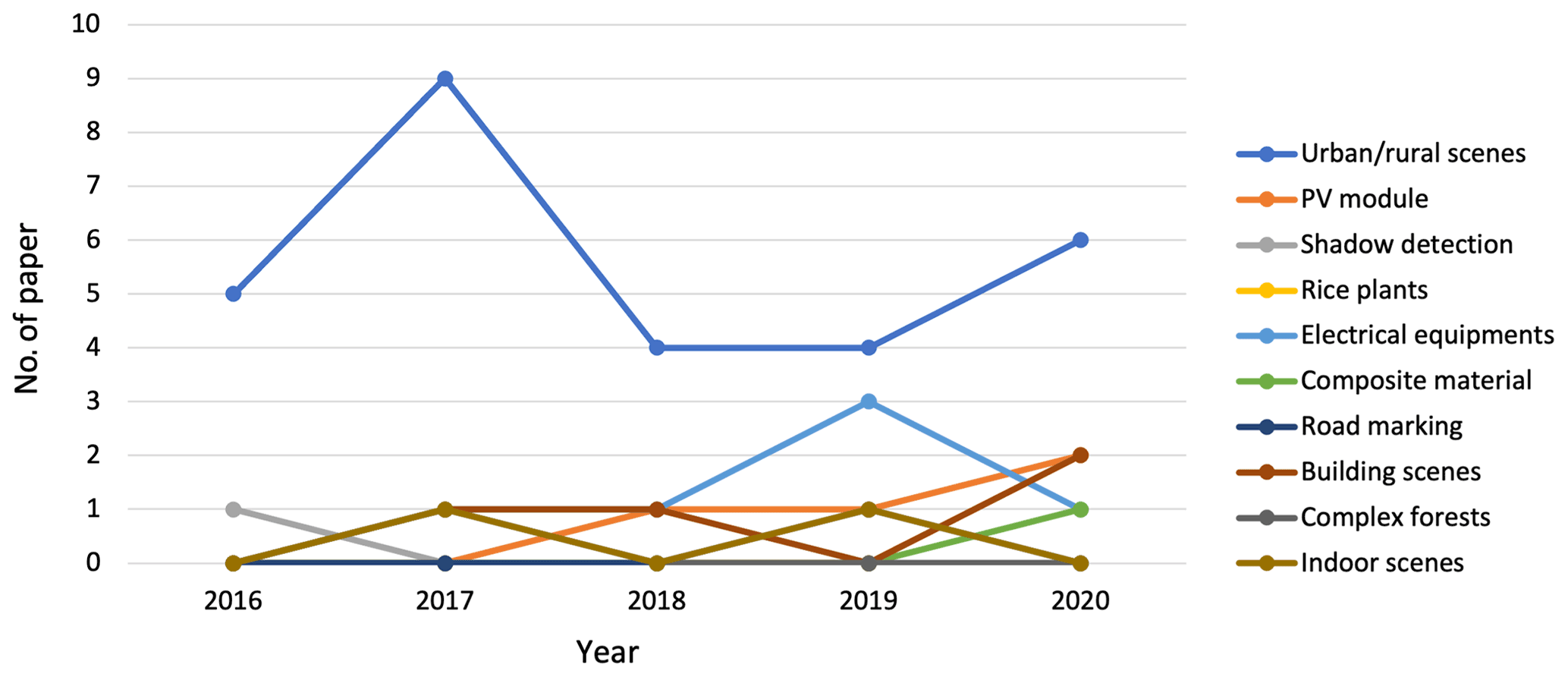
Taking into account the research mentioned in this paper, we have identified 10 different aspects (urban–rural scenes, PV module, shadow detection, rice plants, electrical equipment, composite material, road marking, building scenes, complex forests, and indoor scenes).
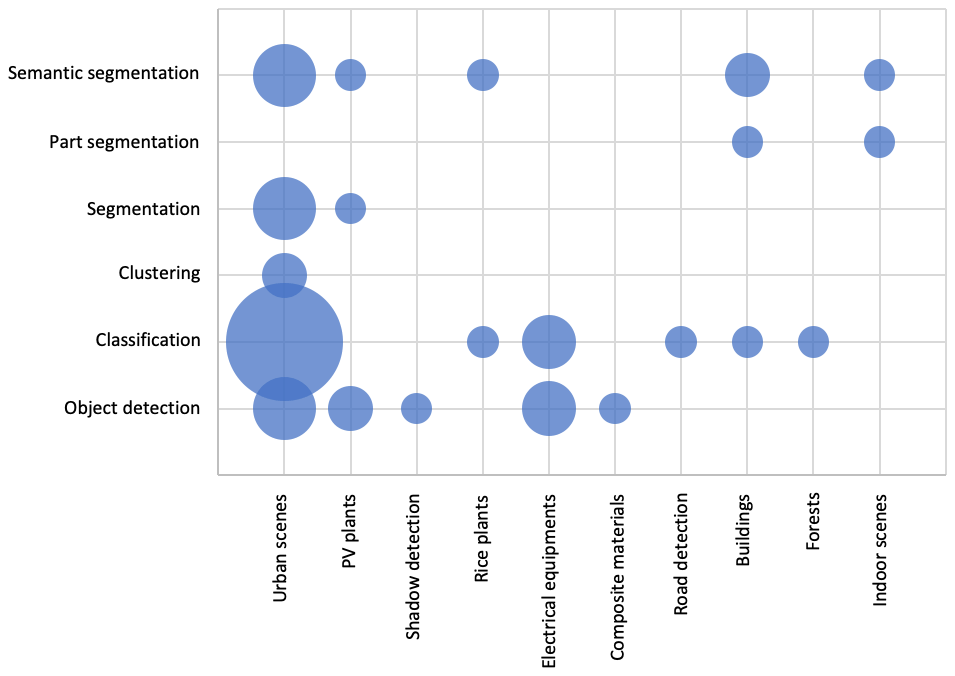
The analysis shown in Fig. 9 considers each AI-based task based on the application domain. This graph directly comprises the application domain and geomatics data. RGB-D and PC data are most commonly used in different domains, although RGB-D data are most commonly used in urban–rural scenes. It is fair to say that a clear subdivision among the countless application domains in geomatic is impervious; notwithstanding, Fig. 9 highlights the fact that clustering and classification tasks are currently performing best in urban scenes, maybe due to the vast use of geomatic data in such environments. PV plant applications, however, are explored, indicating that AI approaches might be very useful for decision-making in environmental applications, as PV plants are. The remaining data are sparse, highlighting the need for future investigations to outline a straightforward line of research.
The analysis in Fig. 10 raises an additional question: does the application domain change over the years? We can confirm that there is no relation between the application domain and the year, although there is an increase in the application of urban–rural scenes, mainly due to the type of associated data.
Notwithstanding the success of AI in the geomatics, important caveats and limitations have hampered its wider adoption and impact. Figure 11 presents a radar chart that considers the tasks based on the kind of data. This summarises the choice of task with available geomatics data.

Figure 11Spider chart representing the distribution of AI-based approaches in relation to the specific geomatics data.
Exploiting AI for the interpretation of complex geomatics data comes with many challenges, including the variability of the data source, the management of heterogeneous data, the different scales of representation, and the purpose of data processing. However, the more pronounced challenges related to the application can be categorised as follows.
-
Lack of available dataset. Regardless of the topic and/or the kind of data in the training phase (given the assumption that DL models can be arranged to fit a specific task), there is a lack of available datasets in the literature to be used as benchmarks. The great interest demonstrated by the research community in utilising geomatics data with learning-based approaches is hampered by the scepticism in sharing labelled datasets. It is well known that ML and DL are data-driven techniques that perform better as the number of input samples increases. Attempts to solve this problem have involved the generation of synthetic datasets (Pierdicca et al., 2019a; Morbidoni et al., 2020). Recently, generative models have proven to be effective for this task. Generative adversarial networks (GANs) are an appealing DL approach developed in 2014 by Goodfellow et al. (2014). GANs are an unsupervised deep learning approach in which two neural networks challenge each other, and each of the two networks improves at its given task with each iteration. For the image generation issue, the generator begins with Gaussian noise to generate images, and the discriminator determines how valuable the generated images are. This process proceeds until the generator development of outputs. GANs have been used to generate artificial images and videos as well as to generate point clouds (Vondrick et al., 2016; Sun et al., 2020; Rossi et al., 2021). Despite exceptional results in supervised learning since the DL developments, collecting enough data to train the models remains a challenge, and some methods have been developed to train models with little or no data. Zero-shot learning (ZSL) is the task of training a model in some (seen) classes and testing it in other (unseen) classes. Good results have been achieved in ZSL, especially with the adoption of generative methods, but it is unclear whether these results are generalisable to the real world. Moreover, self-supervision as an auxiliary task to the main supervised few-shot learning is considered to be an equivalent method to learning a transferable feature representation from limited examples, since self-supervision can contribute to additional structural information easily ignored by the main task.
-
Domain-dependent models. Regarding its respective geomatics compartment, when there is no all-in-one solution for every task, each AI-based model should be chosen according to the task one is attempting to solve. In other words, as AI improves, the need has emerged to understand how to make such models effective, choosing them according to the kind of data for which they have been designed. Integrating the knowledge of domain experts into AI models increases the reliability and the robustness of algorithms, making decisions more accurate. Moreover, the knowledge acquired for one task can be used to solve related ones thanks to transferring learning strategies. Transfer learning allows leveraging knowledge (such as features and weights) from previously trained AI models for training newer models and even tackling problems like having less data for the newer task. Future models should integrate process-based and machine learning approaches. Data-driven machine learning approaches to geoscientific research will not replace physical modelling but strongly complement and enrich it. Specifically, synergies between physical and data-driven models are needed, with the ultimate goal of hybrid modelling approaches. Importantly, machine learning research will benefit from plausible physically based relationships derived from natural phenomena.
-
Data preprocessing. Broadly speaking, geomatics data have intrinsic features that make them very challenging for DL, especially convolutional neural networks. The reason for this is that AI is intended to utilise data that are ordered, regular, and on a structured grid. This means that data should be ordered, and pre-processing operations are still time-consuming. This represents one of the main bottlenecks, as it requires the presence of an expert for every single application domain.
-
Hardware limitations. Despite the growing computational capabilities of better-performing CPUs and the advances in distributed and parallel high-performance computing (HPC), the computational costs of the above-mentioned tasks remain high. We are not still at a stage where the ratio between time gained and resources spent is in balance, making the use of AI-based methods unhelpful at times compared with time-consuming but more affordable manual solutions.
AI is thoroughly changing several application domains. In the geospatial domain, the data characteristics are particularly suitable for ML and DL approaches. Above all, ML- and DL-based interpretation of 3D geomatics enables us to transcend explicit geospatial modelling and therefore to overcome complex, heuristics-based reconstructions and model-based abstractions. This paper provides insight into new trends, techniques, and methods of GeoAI. In particular, a thorough survey of the literature related to the use of AI in geomatics and its methods has been presented, with a particular focus on ML and DL methods. Considering the last years, we can see that there was mainly an increase in RGB-D data and a small reduction of IRT data compared to the previous year. IRT data increased starting in 2017 until 2019, and then in 2020, it had a reduction. Trajectories and HSI and MSI data were mainly an object of research in 2016 and 2017, and then there was a reduction until 2020 when the topic received renewed attention. There was an absence of IRT and PC in 2016, and this subject has been extensively studied, particularly in recent years. The advancing application areas of point cloud processing have already covered not only conventional fields in geospatial analysis, but also include civil engineering, manufacturing, transportation, construction, forestry, ecology, and mechanical engineering, becoming more affordable, more versatile, and thus more studied and examined. Specific emphasis has been given to RGB-D images, thermal images, HSI and MSI, and point cloud analysis and management. AI techniques offer a promising solution to system development and rapid innovation. Further, AI approaches have addressed various challenges, such as point cloud classification, semantic segmentation object detection, and image classification. Methods and techniques for each kind of geomatics data have been analysed, the main paths have been summarised, and their contributions have been highlighted. The reviewed approaches have been categorised and compared from multiple perspectives, pointing out their advantages and disadvantages. Finally, several interesting examples of the GeoAI applications have been presented along with input patterns, pattern classes, and the applied method. We are confident that this review offers rich information and improves the understanding of the research issues related to the use of AI with geomatics data, as well as helping to inform researchers about whether and how AI methods and techniques could help in the creation of applications in various fields. This paper thus paves the way for further research and pinpoints key gaps that serve to provide insights for future improvements, especially considering the complexity introduced by image fusion methods and multi-task learning (S. Li et al., 2017; Laska and Blankenbach, 2022). Future research directions include the improvement of the algorithms to use other comprehensive features, thereby achieving better performance. Moreover, as these models were considered “black box” operators, they need to be interpretable and explainable. The perception of DNNs as black box algorithms makes it difficult to ethically justify their use in high-stake decisions, especially in the case of failure. The adverse effect of black-box-ness is that transparency becomes difficult in the search for a direct understanding of the mechanism by which a model works. Thus, the introduction of interpretability and explainability techniques is crucial, including the visualisation of the results for analysis by humans. Otherwise, domain experts would be hesitant to use techniques that are not straightforwardly interpretable, tractable, and trustworthy given the increasing request for ethical AI. We aim to continue advancing the field now that we have understood its low-maturity but nevertheless promising nature.
No datasets were used in this article.
Conceptualisation was done by RP and MP. RP and MP were responsible for the motivation and research question. RP and MP handled the research strategy definition. MP was responsible for data curation and RP for data preparation. RP and MP contributed to the results, analysis, and discussion sections. Both authors have read and agreed to the published version of the paper.
The contact author has declared that neither they nor their co-authors have any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This paper was edited by Jean Dumoulin and reviewed by two anonymous referees.
Adegun, A., Akande, N., Ogundokun, R., and Asani, E.: Image segmentation and classification of large scale satellite imagery for land use: a review of the state of the arts, Int. J. Civ. Eng. Technol, 9, 1534–1541, 2018. a
Akram, M. W., Li, G., Jin, Y., Chen, X., Zhu, C., and Ahmad, A.: Automatic detection of photovoltaic module defects in infrared images with isolated and develop-model transfer deep learning, Sol. Energy, 198, 175–186, 2020. a, b
Al-Habaibeh, A., Sen, A., and Chilton, J.: Evaluation tool for the thermal performance of retrofitted buildings using an integrated approach of deep learning artificial neural networks and infrared thermography, Energy and Built Environment, 2, 345–365, 2021. a, b
Ali, M. U., Khan, H. F., Masud, M., Kallu, K. D., and Zafar, A.: A machine learning framework to identify the hotspot in photovoltaic module using infrared thermography, Sol. Energy, 208, 643–651, 2020. a
Audebert, N., Le Saux, B., and Lefèvre, S.: Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks, ISPRS J. Photogramm., 140, 20–32, 2018. a
Audebert, N., Le Saux, B., and Lefèvre, S.: Deep learning for classification of hyperspectral data: A comparative review, IEEE Geosci. Remote S., 7, 159–173, 2019. a
Balado, J., Sousa, R., Díaz-Vilariño, L., and Arias, P.: Transfer Learning in urban object classification: Online images to recognize point clouds, Automation in Construction, 111, 103058, https://doi.org/10.1016/j.autcon.2019.103058, 2020. a, b, c
Ball, J. E., Anderson, D. T., and Chan Sr, C. S.: Comprehensive survey of deep learning in remote sensing: theories, tools, and challenges for the community, J. Appl. Remote Sens., 11, 042609, https://doi.org/10.1117/1.JRS.11.042609, 2017. a
Bang, H.-T., Park, S., and Jeon, H.: Defect identification of composites via thermography and deep learning techniques, Compos. Struct., 246, 112405 pp., https://doi.org/10.1016/j.compstruct.2020.112405, 2020. a
Baqersad, J., Poozesh, P., Niezrecki, C., and Avitabile, P.: Photogrammetry and optical methods in structural dynamics–A review, Mech. Syst. Signal Pr., 86, 17–34, 2017. a
Bian, J., Tian, D., Tang, Y., and Tao, D.: A survey on trajectory clustering analysis, arXiv [preprint] arXiv:1802.06971, 2018. a
Bian, J., Tian, D., Tang, Y., and Tao, D.: Trajectory data classification: A review, ACM T. Intel. Syst. Tec., 10, 1–34, 2019. a
Blais, J. R. and Esche, H.: Geomatics and the new cyber-infrastructure, Geomatica, 62, 11–22, 2008. a
Böhler, W. and Heinz, G.: Documentation, surveying, photogrammetry, in: XVII CIPA Symposium, Recife, Olinda, Brazil, vol. 1, 3–6 October 1999, https://www.cipaheritagedocumentation.org/wp-content/uploads/2018/11/Boehler-Heinz-Documentation-surveying-photogrammetry.pdf (last access: 25 May 2022), 1999. a
Boongoen, T. and Iam-On, N.: Cluster ensembles: A survey of approaches with recent extensions and applications, Computer Science Review, 28, 1–25, 2018. a
Can, G., Mantegazza, D., Abbate, G., Chappuis, S., and Giusti, A.: Semantic segmentation on Swiss3DCities: A benchmark study on aerial photogrammetric 3D pointcloud dataset, Pattern Recogn. Lett., 150, 108–114, 2021. a
Chellamuthu, S. and Sekaran, E. C.: Fault detection in electrical equipment’s images by using optimal features with deep learning classifier, Multimed. Tools Appl., 78, 27333–27350, 2019. a, b
Chen, L.-C., Papandreou, G., Kokkinos, I., Murphy, K., and Yuille, A. L.: Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs, IEEE T. Pattern Anal., 40, 834–848, 2017. a
Chen, Y., Jiang, H., Li, C., Jia, X., and Ghamisi, P.: Deep feature extraction and classification of hyperspectral images based on convolutional neural networks, IEEE T. Geosci. Remote, 54, 6232–6251, 2016. a, b
Chen, Y., Xiong, Y., Zhang, B., Zhou, J., and Zhang, Q.: 3D point cloud semantic segmentation toward large-scale unstructured agricultural scene classification, Comput. Electron. Agr., 190, 106445, https://doi.org/10.1016/j.compag.2021.106445, 2021. a
Chu, H., Ma, W.-C., Kundu, K., Urtasun, R., and Fidler, S.: Surfconv: Bridging 3d and 2d convolution for rgbd images, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018, 3002–3011, https://doi.org/10.1109/cvpr.2018.00317, 2018. a
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., and Schiele, B.: The cityscapes dataset for semantic urban scene understanding, in: Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016, 3213–3223, https://doi.org/10.1109/cvpr.2016.350, 2016. a
Czerniawski, T. and Leite, F.: Automated segmentation of RGB-D images into a comprehensive set of building components using deep learning, Adv. Eng. Inform., 45, 101131, https://doi.org/10.1016/j.aei.2020.101131, 2020. a, b
Dabiri, S., Lu, C.-T., Heaslip, K., and Reddy, C. K.: Semi-supervised deep learning approach for transportation mode identification using GPS trajectory data, IEEE T. Knowl. Data Eng., 32, 1010–1023, 2019. a, b
Dabiri, S., Marković, N., Heaslip, K., and Reddy, C. K.: A deep convolutional neural network based approach for vehicle classification using large-scale GPS trajectory data, Transport. Res. C-Emer., 116, 102644, https://doi.org/10.1016/j.trc.2020.102644, 2020. a, b
Di Stefano, F., Chiappini, S., Gorreja, A., Balestra, M., and Pierdicca, R.: Mobile 3D scan LiDAR: a literature review, Geomatics, Natural Hazards and Risk, 12, 2387–2429, 2021. a
Duan, Y., Liu, S., Hu, C., Hu, J., Zhang, H., Yan, Y., Tao, N., Zhang, C., Maldague, X., Fang, Q., Ibarra-Castanedo, C., Chen, D., Li, X., and Meng, J.: Automated defect classification in infrared thermography based on a neural network, NDT & E Int., 107, 102147, https://doi.org/10.1016/j.ndteint.2019.102147, 2019. a, b, c
Duan, Z., Yang, Y., Zhang, K., Ni, Y., and Bajgain, S.: Improved deep hybrid networks for urban traffic flow prediction using trajectory data, IEEE Access, 6, 31820–31827, 2018. a, b
Dunderdale, C., Brettenny, W., Clohessy, C., and van Dyk, E. E.: Photovoltaic defect classification through thermal infrared imaging using a machine learning approach, Progress in Photovoltaics: Research and Applications, 28, 177–188, 2020. a
Elhamdadi, H., Canavan, S., and Rosen, P.: AffectiveTDA: Using Topological Data Analysis to Improve Analysis and Explainability in Affective Computing, IEEE T. Vis. Comput. Gr., 28, 769–779, https://doi.org/10.1109/TVCG.2021.3114784, 2021. a
Endo, Y., Toda, H., Nishida, K., and Ikedo, J.: Classifying spatial trajectories using representation learning, International Journal of Data Science and Analytics, 2, 107–117, 2016. a, b
Espinosa, A. R., Bressan, M., and Giraldo, L. F.: Failure signature classification in solar photovoltaic plants using RGB images and convolutional neural networks, Renew. Energ., 162, 249–256, 2020. a, b
Felicetti, A., Paolanti, M., Zingaretti, P., Pierdicca, R., and Malinverni, E. S.: Mo. Se.: Mosaic image segmentation based on deep cascading learning, Virtual Archaeology Review, 12, 25–38, https://doi.org/10.4995/var.2021.14179, 2021. a
Fuhrman, J. D., Gorre, N., Hu, Q., Li, H., El Naqa, I., and Giger, M. L.: A review of explainable and interpretable AI with applications in COVID-19 imaging, Med. Phys., 49, 1–14, https://doi.org/10.1002/mp.15359, 2021. a
Fu, K.-S. and Mui, J.: A survey on image segmentation, Pattern recognition, 13, 3–16, 1981. a
Fu, L., Gao, F., Wu, J., Li, R., Karkee, M., and Zhang, Q.: Application of consumer RGB-D cameras for fruit detection and localization in field: A critical review, Comput. Electron. Agr., 177, 105687, https://doi.org/10.1016/j.compag.2020.105687, 2020. a
Gade, R. and Moeslund, T. B.: Thermal cameras and applications: a survey, Mach. Vision Appl., 25, 245–262, 2014. a
Geng, X., Ji, S., Lu, M., and Zhao, L.: Multi-Scale Attentive Aggregation for LiDAR Point Cloud Segmentation, Remote Sensing, 13, 691, https://doi.org/10.3390/rs13040691, 2021. a
Ghamisi, P., Plaza, J., Chen, Y., Li, J., and Plaza, A. J.: Advanced spectral classifiers for hyperspectral images: A review, IEEE Geosci. Remote S., 5, 8–32, 2017. a
Gomarasca, M. A.: Basics of geomatics, Applied Geomatics, 2, 137–146, 2010. a
Gong, X., Yao, Q., Wang, M., and Lin, Y.: A deep learning approach for oriented electrical equipment detection in thermal images, IEEE Access, 6, 41590–41597, 2018. a, b, c
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., and Bengio, Y.: Generative adversarial nets, Adv. Neur. Inf., 27, 2672–2680, 2014. a
Goodfellow, I., Bengio, Y., Courville, A., and Bengio, Y.: Deep learning, vol. 1, MIT press Cambridge, ISBN: 9780262035613, 2016. a
Greco, A., Pironti, C., Saggese, A., Vento, M., and Vigilante, V.: A deep learning based approach for detecting panels in photovoltaic plants, in: Proceedings of the 3rd International Conference on Applications of Intelligent Systems, Las Palmas de Gran Canaria, Spain, 7–9 January 2020, 1–7, https://doi.org/10.1145/3378184.3378185, 2020. a, b
Grilli, E., Menna, F., and Remondino, F.: A REVIEW OF POINT CLOUDS SEGMENTATION AND CLASSIFICATION ALGORITHMS, Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci., XLII-2/W3, 339–344, https://doi.org/10.5194/isprs-archives-XLII-2-W3-339-2017, 2017. a
Groves, P. D.: Principles of GNSS, inertial, and multisensor integrated navigation systems, [Book review], IEEE Aero. El. Syst. Mag., 30, 26–27, 2015. a
Guo, Y., Liu, Y., Oerlemans, A., Lao, S., Wu, S., and Lew, M. S.: Deep learning for visual understanding: A review, Neurocomputing, 187, 27–48, 2016. a
Guo, Y., Wang, H., Hu, Q., Liu, H., Liu, L., and Bennamoun, M.: Deep learning for 3d point clouds: A survey, IEEE T. Pattern Anal., 43, 4338–4364, https://doi.org/10.1109/tpami.2020.3005434, 2020. a
Habtemichael, F. G. and Cetin, M.: Short-term traffic flow rate forecasting based on identifying similar traffic patterns, Transport. Res. C-Emer., 66, 61–78, 2016. a, b
Han, J., Shao, L., Xu, D., and Shotton, J.: Enhanced computer vision with microsoft kinect sensor: A review, IEEE T. Cybernetics, 43, 1318–1334, 2013. a, b
Hong, D., Gao, L., Yao, J., Zhang, B., Plaza, A., and Chanussot, J.: Graph convolutional networks for hyperspectral image classification, IEEE T. Geosci. Remote, 59, 5966–5978, https://doi.org/10.1109/tgrs.2020.3015157, 2020a. a, b
Hong, D., Yokoya, N., Xia, G.-S., Chanussot, J., and Zhu, X. X.: X-ModalNet: A semi-supervised deep cross-modal network for classification of remote sensing data, ISPRS J. Photogramm., 167, 12–23, 2020b. a, b, c
James, J.: Travel Mode Identification With GPS Trajectories Using Wavelet Transform and Deep Learning, IEEE T. Intell. Transp., 22, 1093–1103, https://doi.org/10.1109/tits.2019.2962741, 2020. a, b
Jamiruddin, R., Sari, A. O., Shabbir, J., and Anwer, T.: RGB-depth SLAM review, arXiv [preprint], 1805.07696, 2018. a
Janowicz, K., Gao, S., McKenzie, G., Hu, Y., and Bhaduri, B.: GeoAI: spatially explicit artificial intelligence techniques for geographic knowledge discovery and beyond, 34, 625–636, https://doi.org/10.1080/13658816.2019.1684500, 2020. a
Jiang, X., de Souza, E. N., Pesaranghader, A., Hu, B., Silver, D. L., and Matwin, S.: TrajectoryNet: an embedded GPS trajectory representation for point-based classification using recurrent neural networks, in: Proceedings of the 27th Annual International Conference on Computer Science and Software Engineering, Markham, Ontario, Canada, 6–8 November 2017, 192–200, https://dl.acm.org/doi/10.5555/3172795.3172817 (last access: 25 May 2022), 2017. a, b
Jiang, Z.: A survey on spatial prediction methods, IEEE T. Knowl. Data En., 31, 1645–1664, 2018. a
Kandeal, A., Elkadeem, M., Thakur, A. K., Abdelaziz, G. B., Sathyamurthy, R., Kabeel, A., Yang, N., and Sharshir, S. W.: Infrared thermography-based condition monitoring of solar photovoltaic systems: A mini review of recent advances, Sol. Energy, 223, 33–43, 2021. a
Kattenborn, T., Leitloff, J., Schiefer, F., and Hinz, S.: Review on Convolutional Neural Networks (CNN) in vegetation remote sensing, ISPRS J. Photogramm., 173, 24–49, 2021. a
Kirimtat, A. and Krejcar, O.: A review of infrared thermography for the investigation of building envelopes: Advances and prospects, Energ. Buildings, 176, 390–406, 2018. a
Konecny, G.: Recent global changes in geomatics education, Int. Arch. Photogramm., 34, 9–14, 2002. a
Kothari, P., Kreiss, S., and Alahi, A.: Human trajectory forecasting in crowds: A deep learning perspective, IEEE T. Intell. Transp., April 2021, 1–15, https://doi.org/10.1109/tits.2021.3069362, 2021. a
Krizhevsky, A., Sutskever, I., and Hinton, G. E.: Imagenet classification with deep convolutional neural networks, Adv. Neur. In., 25, 1097–1105, 2012. a
Laska, M. and Blankenbach, J.: Multi-Task Neural Network for Position Estimation in Large-Scale Indoor Environments, IEEE Access, 10, 26024–26032, 2022. a
LeCun, Y., Bengio, Y., and Hinton, G.: Deep learning, Nature, 521, 436, https://doi.org/10.1038/nature14539, 2015. a, b
Lee, J. S., Park, J., and Ryu, Y.-M.: Semantic segmentation of bridge components based on hierarchical point cloud model, Automat. Constr., 130, 103847, https://doi.org/10.1016/j.autcon.2021.103847, 2021. a
Lemmens, M.: Terrestrial laser scanning, Geo-information, 5, 101–121, 2011. a
Liciotti, D., Paolanti, M., Frontoni, E., and Zingaretti, P.: People detection and tracking from an RGB-D camera in top-view configuration: review of challenges and applications, in: International Conference on Image Analysis and Processing, Catania, Italy, 11–15 September 2017, 207–218, https://doi.org/10.1007/978-3-319-70742-6_20, 2017. a
Li, K., Wan, G., Cheng, G., Meng, L., and Han, J.: Object detection in optical remote sensing images: A survey and a new benchmark, ISPRS J. Photogramm., 159, 296–307, 2020. a, b
Li, L., Qian, B., Lian, J., Zheng, W., and Zhou, Y.: Traffic scene segmentation based on RGB-D image and deep learning, IEEE T. Intell. Transp., 19, 1664–1669, 2017. a, b
Liscio, E., Guryn, H., and Stoewner, D.: Accuracy and repeatability of trajectory rod measurement using laser scanners, J. Forensic Sci., 63, 1506–1515, 2018. a
Li, S., Kang, X., Fang, L., Hu, J., and Yin, H.: Pixel-level image fusion: A survey of the state of the art, information Fusion, 33, 100–112, 2017. a
Li, S., Song, W., Fang, L., Chen, Y., Ghamisi, P., and Benediktsson, J. A.: Deep learning for hyperspectral image classification: An overview, IEEE T. Geosci. Remote, 57, 6690–6709, 2019. a
Liu, L., Ouyang, W., Wang, X., Fieguth, P., Chen, J., Liu, X., and Pietikäinen, M.: Deep learning for generic object detection: A survey, Int. J. Comput. Vision, 128, 261–318, 2020. a
Liu, P., Zhang, H., and Eom, K. B.: Active deep learning for classification of hyperspectral images, IEEE J-STARS, 10, 712–724, 2016. a, b
Li, W., Wu, G., and Du, Q.: Transferred deep learning for anomaly detection in hyperspectral imagery, IEEE Geosci. Remote S., 14, 597–601, 2017. a, b
Li, X., Yang, Q., Lou, Z., and Yan, W.: Deep learning based module defect analysis for large-scale photovoltaic farms, IEEE T. Energy Conver., 34, 520–529, 2018. a, b
Li, Y., Zhang, H., Xue, X., Jiang, Y., and Shen, Q.: Deep learning for remote sensing image classification: A survey, Wires Data Min. Knowl., 8, e1264, https://doi.org/10.1002/widm.1264, 2018. a
Li, Y., Peng, C., Chen, Y., Jiao, L., Zhou, L., and Shang, R.: A deep learning method for change detection in synthetic aperture radar images, IEEE T. Geosci. Remote, 57, 5751–5763, 2019. a, b
Li, Y., Ma, L., Zhong, Z., Liu, F., Chapman, M. A., Cao, D., and Li, J.: Deep learning for LiDAR point clouds in autonomous driving: a review, IEEE T. Neur. Net. Lear., 32, 3412–3432, https://doi.org/10.1109/tnnls.2020.3015992, 2020. a
Luo, Q., Gao, B., Woo, W. L., and Yang, Y.: Temporal and spatial deep learning network for infrared thermal defect detection, NDT & E Int., 108, 102164, https://doi.org/10.1016/j.ndteint.2019.102164, 2019. a, b
Malinverni, E. S., Pierdicca, R., Paolanti, M., Martini, M., Morbidoni, C., Matrone, F., and Lingua, A.: DEEP LEARNING FOR SEMANTIC SEGMENTATION OF 3D POINT CLOUD, Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci., XLII-2/W15, 735–742, https://doi.org/10.5194/isprs-archives-XLII-2-W15-735-2019, 2019. a
Martín-Jiménez, J. A., Zazo, S., Justel, J. J. A., Rodríguez-Gonzálvez, P., and González-Aguilera, D.: Road safety evaluation through automatic extraction of road horizontal alignments from Mobile LiDAR System and inductive reasoning based on a decision tree, ISPRS J. Photogramm., 146, 334–346, 2018. a
Matrone, F., Grilli, E., Martini, M., Paolanti, M., Pierdicca, R., and Remondino, F.: Comparing machine and deep learning methods for large 3D heritage semantic segmentation, ISPRS Int. Geo-Inf., 9, 535, https://doi.org/10.3390/ijgi9090535, 2020a. a
Matrone, F., Lingua, A., Pierdicca, R., Malinverni, E. S., Paolanti, M., Grilli, E., Remondino, F., Murtiyoso, A., and Landes, T.: A BENCHMARK FOR LARGE-SCALE HERITAGE POINT CLOUD SEMANTIC SEGMENTATION, Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci., XLIII-B2-2020, 1419–1426, https://doi.org/10.5194/isprs-archives-XLIII-B2-2020-1419-2020, 2020b. a
Mehonic, A. and Kenyon, A. J.: Brain-inspired computing needs a master plan, Nature, 604, 255–260, 2022. a
Mendili, L. E., Puissant, A., Chougrad, M., and Sebari, I.: Towards a multi-temporal deep learning approach for mapping urban fabric using sentinel 2 images, Remote Sensing, 12, 423, 2020. a
Minaee, S., Boykov, Y. Y., Porikli, F., Plaza, A. J., Kehtarnavaz, N., and Terzopoulos, D.: Image segmentation using deep learning: A survey, IEEE T. Pattern Anal., February 2021, p. 1, https://doi.org/10.1109/TPAMI.2021.3059968, 2021. a
Mitchell, T: Machine Learning, New York, McGraw-hill, ISBN: 978-0-07-042807-2, 1997. a
Morbidoni, C., Pierdicca, R., Paolanti, M., Quattrini, R., and Mammoli, R.: Learning from Synthetic Point Cloud Data for Historical Buildings Semantic Segmentation, Journal on Computing and Cultural Heritage (JOCCH), 13, 1–16, 2020. a
Movia, A., Beinat, A., and Crosilla, F.: Shadow detection and removal in RGB VHR images for land use unsupervised classification, ISPRS J. Photogramm., 119, 485–495, 2016. a, b
Naha, S., Xiao, Q., Banik, P., Alimoor Reza, M., and Crandall, D. J.: Pose-Guided Knowledge Transfer for Object Part Segmentation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020, 906–907, https://doi.org/10.1109/cvprw50498.2020.00461, 2020. a
Nasiri, A., Taheri-Garavand, A., Omid, M., and Carlomagno, G. M.: Intelligent fault diagnosis of cooling radiator based on deep learning analysis of infrared thermal images, Appl. Therm. Eng., 163, 114410, https://doi.org/10.1016/j.applthermaleng.2019.114410, 2019. a, b
Ongsulee, P.: Artificial intelligence, machine learning and deep learning, in: 2017 15th International Conference on ICT and Knowledge Engineering (ICT&KE), Bangkok, Thailand, November 2017, 22–24, 1–6, https://doi.org/10.1109/ICTKE.2017.8259629, 2017. a
Özdemir, E. and Remondino, F.: CLASSIFICATION OF AERIAL POINT CLOUDS WITH DEEP LEARNING, Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci., XLII-2/W13, 103–110, https://doi.org/10.5194/isprs-archives-XLII-2-W13-103-2019, 2019. a
Pang, Y., Wang, W., Du, L., Zhang, Z., Liang, X., Li, Y., and Wang, Z.: Nyström-based spectral clustering using airborne LiDAR point cloud data for individual tree segmentation, Int. J. Digit. Earth, 14, 1452–1476, 2021. a
Paolanti, M. and Frontoni, E.: Multidisciplinary Pattern Recognition applications: A review, Computer Science Review, 37, 100276, https://doi.org/10.1016/j.cosrev.2020.100276, 2020. a
Paolanti, M., Pierdicca, R., Martini, M., Di Stefano, F., Morbidoni, C., Mancini, A., Malinverni, E. S., Frontoni, E., and Zingaretti, P.: Semantic 3D Object Maps for Everyday Robotic Retail Inspection, in: International Conference on Image Analysis and Processing, Trento, Italy, 9–13 September 2019, 263–274, https://doi.org/10.1007/978-3-030-30754-7_27, 2019. a
Pierdicca, R., Malinverni, E. S., Piccinini, F., Paolanti, M., Felicetti, A., and Zingaretti, P.: DEEP CONVOLUTIONAL NEURAL NETWORK FOR AUTOMATIC DETECTION OF DAMAGED PHOTOVOLTAIC CELLS, Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci., XLII-2, 893–900, https://doi.org/10.5194/isprs-archives-XLII-2-893-2018, 2018. a
Pierdicca, R., Mameli, M., Malinverni, E. S., Paolanti, M., and Frontoni, E.: Automatic Generation of Point Cloud Synthetic Dataset for Historical Building Representation, in: International Conference on Augmented Reality, Virtual Reality and Computer Graphics, Lecce, Italy, 7–10 September 2019, 203–219, https://doi.org/10.1007/978-3-030-25965-5_16, 2019a. a
Pierdicca, R., Paolanti, M., Vaira, R., Marcheggiani, E., Malinverni, E. S., and Frontoni, E.: Identifying the use of a park based on clusters of visitors' movements from mobile phone data, Journal of Spatial Information Science, 2019, 29–52, 2019b. a, b
Pierdicca, R., Paolanti, M., Felicetti, A., Piccinini, F., and Zingaretti, P.: Automatic Faults Detection of Photovoltaic Farms: solAIr, a Deep Learning-Based System for Thermal Images, Energies, 13, 6496, https://doi.org/10.3390/en13246496, 2020a. a
Pierdicca, R., Paolanti, M., Matrone, F., Martini, M., Morbidoni, C., Malinverni, E. S., Frontoni, E., and Lingua, A. M.: Point Cloud Semantic Segmentation Using a Deep Learning Framework for Cultural Heritage, Remote Sensing, 12, 1005, https://doi.org/10.3390/rs12061005, 2020b. a, b
Qi, C. R., Su, H., Mo, K., and Guibas, L. J.: Pointnet: Deep learning on point sets for 3d classification and segmentation, in: Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017, 652–660, https://doi.org/10.1109/cvpr.2017.16, 2017a. a, b, c, d
Qi, C. R., Yi, L., Su, H., and Guibas, L. J.: Pointnet: Deep hierarchical feature learning on point sets in a metric space, in: Advances in neural information processing systems, Long Beach, California, USA, 4–9 December 2017, 5099–5108, https://proceedings.neurips.cc/paper/2017/hash/d8bf84be3800d12f74d8b05e9b89836f-Abstract.html (last access: 31 May 2022), 2017b. a
Redmon, J., Divvala, S., Girshick, R., and Farhadi, A.: You only look once: Unified, real-time object detection, in: Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016, 779–788, https://doi.org/10.1109/cvpr.2016.91, 2016. a
Reichstein, M., Camps-Valls, G., Stevens, B., Jung, M., Denzler, J., Carvalhais, N., Prabhat, P.: Deep learning and process understanding for data-driven Earth system science, Nature, 566, 195–204, 2019. a
Rossi, L., Ajmar, A., Paolanti, M., and Pierdicca, R.: Vehicle trajectory prediction and generation using LSTM models and GANs, Plos one, 16, e0253868, https://doi.org/10.1371/journal.pone.0253868, 2021. a
Sharma, R. C., Hara, K., and Hirayama, H.: A machine learning and cross-validation approach for the discrimination of vegetation physiognomic types using satellite based multispectral and multitemporal data, Scientifica, 2017, 9806479, https://doi.org/10.1155/2017/9806479, 2017. a, b
Shen, Z., Liang, H., Lin, L., Wang, Z., Huang, W., and Yu, J.: Fast Ground Segmentation for 3D LiDAR Point Cloud Based on Jump-Convolution-Process, Remote Sensing, 13, 3239, https://doi.org/10.3390/rs13163239, 2021. a
Shi, Z. and Pun-Cheng, L. S.: Spatiotemporal data clustering: a survey of methods, ISPRS Int. Geo-Inf., 8, 112, https://doi.org/10.3390/ijgi8030112, 2019. a
Siddique, A. and Afanasyev, I.: Deep Learning-based Trajectory Estimation of Vehicles in Crowded and Crossroad Scenarios, in: 2021 28th Conference of Open Innovations Association (FRUCT), Moskva, Russia, 25–29 January 2021, 413–423, https://doi.org/10.23919/fruct50888.2021.9347580, 2021. a
Signoroni, A., Savardi, M., Baronio, A., and Benini, S.: Deep learning meets hyperspectral image analysis: a multidisciplinary review, Journal of Imaging, 5, 52, https://doi.org/10.3390/jimaging5050052, 2019. a
Sultana, F., Sufian, A., and Dutta, P.: Evolution of image segmentation using deep convolutional neural network: A survey, Knowl.-Based Syst., 201–202, p. 106062, https://doi.org/10.1016/j.knosys.2020.106062, 2020. a
Sun, Y., Wang, Y., Liu, Z., Siegel, J., and Sarma, S.: Pointgrow: Autoregressively learned point cloud generation with self-attention, in: The IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020, 61–70, https://doi.org/10.1109/wacv45572.2020.9093430, 2020. a
Tajwar, T., Hossain, S. F., Mobin, O. H., Islam, M., Khan, F. R., and Rahman, M. M.: Infrared Thermography Based Hotspot Detection Of Photovoltaic Module using YOLO, in: 2021 IEEE 12th Energy Conversion Congress & Exposition-Asia (ECCE-Asia), Singapore, 24–27 May 2021, 1542–1547, https://doi.org/10.1109/ecce-asia49820.2021.9478998, 2021. a
Tan, P.-N., Steinbach, M., and Kumar, V.: Introduction to data mining, Pearson Education India, 2nd edn., Addison-Wesley, ISBN-13: 978-0133128901, 2016. a
Toth, C. and Jóźków, G.: Remote sensing platforms and sensors: A survey, ISPRS J. Photogramm., 115, 22–36, 2016. a
Ullah, I., Yang, F., Khan, R., Liu, L., Yang, H., Gao, B., and Sun, K.: Predictive maintenance of power substation equipment by infrared thermography using a machine-learning approach, Energies, 10, 1987, https://doi.org/10.3390/en10121987, 2017. a, b
Ullah, I., Khan, R. U., Yang, F., and Wuttisittikulkij, L.: Deep learning image-based defect detection in high voltage electrical equipment, Energies, 13, 392, https://doi.org/10.3390/en13020392, 2020. a, b
Vicnesh, J., Oh, S. L., Wei, J. K. E., Ciaccio, E. J., Chua, K. C., Tong, L., and Acharya, U. R.: Thoughts concerning the application of thermogram images for automated diagnosis of dry eye-A review, Infrared Phys. Techn., 106, p. 103271, https://doi.org/10.1016/j.infrared.2020.103271, 2020. a
Vondrick, C., Pirsiavash, H., and Torralba, A.: Generating videos with scene dynamics, in: Adv. Neur. In., 29, 613–621, 2016. a
Wang, H., Wang, Y., Zhang, Q., Xiang, S., and Pan, C.: Gated convolutional neural network for semantic segmentation in high-resolution images, Remote Sensing, 9, 446, https://doi.org/10.3390/rs9050446, 2017. a
Wang, X. and Ji, S.: Roof Plane Segmentation From LiDAR Point Cloud Data Using Region Expansion Based L 0 Gradient Minimization and Graph Cut, IEEE J-STARS, 14, 10101–10116, 2021. a, b
Wang, Y., Sun, Y., Liu, Z., Sarma, S. E., Bronstein, M. M., and Solomon, J. M.: Dynamic graph cnn for learning on point clouds, Acm T. Graphic., 38, 1–12, 2019. a, b, c
Wang, Z., Xu, Y., Yu, J., Xu, G., Fu, J., and Gu, T.: Instance segmentation of point cloud captured by RGB-D sensor based on deep learning, Int. J. Comp. Integ. M., 34, 950–963, 2021. a
Weinmann, M., Schmidt, A., Mallet, C., Hinz, S., Rottensteiner, F., and Jutzi, B.: CONTEXTUAL CLASSIFICATION OF POINT CLOUD DATA BY EXPLOITING INDIVIDUAL 3D NEIGBOURHOODS, ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci., II-3/W4, 271–278, https://doi.org/10.5194/isprsannals-II-3-W4-271-2015, 2015. a
Wen, C., Sun, X., Li, J., Wang, C., Guo, Y., and Habib, A.: A deep learning framework for road marking extraction, classification and completion from mobile laser scanning point clouds, ISPRS J. Photogramm., 147, 178–192, 2019. a, b
Wu, H. and Prasad, S.: Semi-supervised deep learning using pseudo labels for hyperspectral image classification, IEEE T. Image Process., 27, 1259–1270, 2017. a, b
Xiao, A., Yang, X., Lu, S., Guan, D., and Huang, J.: FPS-Net: A convolutional fusion network for large-scale LiDAR point cloud segmentation, ISPRS J. Photogramm., 176, 237–249, 2021. a
Xiao, Y., Wu, J., Lin, Z., and Zhao, X.: A deep learning-based multi-model ensemble method for cancer prediction, Computer Meth. Prog. Bio., 153, 1–9, 2018. a
Xiao, Z., Wang, Y., Fu, K., and Wu, F.: Identifying different transportation modes from trajectory data using tree-based ensemble classifiers, ISPRS Int. Geo-Inf., 6, 57, https://doi.org/10.3390/ijgi6020057, 2017. a, b
Xie, Y., Jiaojiao, T., and Zhu, X.: Linking Points With Labels in 3D: A Review of Point Cloud Semantic Segmentation, IEEE Geosci. Remote S., 8, 38–59, https://doi.org/10.1109/mgrs.2019.2937630 2020. a
Xu, X., Chen, Y., Zhang, J., Chen, Y., Anandhan, P., and Manickam, A.: A novel approach for scene classification from remote sensing images using deep learning methods, Eur. J. Remote Sens., 54, 383–395, 2021. a
Yang, M.-D., Tseng, H.-H., Hsu, Y.-C., and Tsai, H. P.: Semantic segmentation using deep learning with vegetation indices for rice lodging identification in multi-date UAV visible images, Remote Sensing, 12, 633, https://doi.org/10.3390/rs12040633, 2020. a
Yang, X., Stewart, K., Tang, L., Xie, Z., and Li, Q.: A review of GPS trajectories classification based on transportation mode, Sensors, 18, 3741, https://doi.org/10.3390/s18113741, 2018a. a
Yang, X., Ye, Y., Li, X., Lau, R. Y., Zhang, X., and Huang, X.: Hyperspectral image classification with deep learning models, IEEE T. Geosci. Remote, 56, 5408–5423, 2018b. a, b
Yang, Y., Yan, J., Guo, J., Kuang, Y., Yin, M., Wang, S., and Ma, C.: Driving behavior analysis of city buses based on real-time GNSS traces and road information, Sensors, 21, 687, https://doi.org/10.3390/s21030687, 2021. a
Yang, Z., Jiang, W., Xu, B., Zhu, Q., Jiang, S., and Huang, W.: A convolutional neural network-based 3D semantic labeling method for ALS point clouds, Remote Sensing, 9, 936, https://doi.org/10.3390/rs9090936, 2017. a, b
Yan, L., Yoshua, B., and Geoffrey, H.: Deep learning, nature, 521, 436–444, 2015. a
Yousefhussien, M., Kelbe, D. J., Ientilucci, E. J., and Salvaggio, C.: A multi-scale fully convolutional network for semantic labeling of 3D point clouds, ISPRS J. Photogramm., 143, 191–204, 2018. a, b
Yuan, X., Shi, J., and Gu, L.: A review of deep learning methods for semantic segmentation of remote sensing imagery, Expert Syst. Appl., 169, 114417, https://doi.org/10.1016/j.eswa.2020.114417, 2021. a, b, c
Zang, N., Cao, Y., Wang, Y., Huang, B., Zhang, L., and Mathiopoulos, P. T.: Land-use Mapping for High Spatial Resolution Remote Sensing Image via Deep Learning: A Review, IEEE J. Sel. Top. Appl., 14, 5372–5391, https://doi.org/10.1109/jstars.2021.3078631, 2021. a, b
Zhang, C., Atkinson, P. M., George, C., Wen, Z., Diazgranados, M., and Gerard, F.: Identifying and mapping individual plants in a highly diverse high-elevation ecosystem using UAV imagery and deep learning, ISPRS J. Photogramm., 169, 280–291, 2020. a
Zhang, J., Zhao, X., Chen, Z., and Lu, Z.: A Review of Deep Learning-Based Semantic Segmentation for Point Cloud, IEEE Access, 7, 179118–179133, 2019. a, b
Zhang, L. and Zhang, L.: Deep learning-based classification and reconstruction of residential scenes from large-scale point clouds, IEEE T. Geosci. Remote, 56, 1887–1897, 2017. a
Zhang, L., Zhang, L., and Du, B.: Deep learning for remote sensing data: A technical tutorial on the state of the art, IEEE Geoscience and Remote Sensing Magazine, 4, 22–40, 2016. a
Zhang, L., Xia, H., Liu, Q., Wei, C., Fu, D., and Qiao, Y.: Visual Positioning in Indoor Environments Using RGB-D Images and Improved Vector of Local Aggregated Descriptors, ISPRS Int. J. Geo-Inf., 10, 195, https://doi.org/10.3390/ijgi10040195, 2021. a
Zhang, R., Li, G., Li, M., and Wang, L.: Fusion of images and point clouds for the semantic segmentation of large-scale 3D scenes based on deep learning, ISPRS J. Photogramm., 143, 85–96, 2018. a, b
Zhang, R., Xie, P., Wang, C., Liu, G., and Wan, S.: Classifying transportation mode and speed from trajectory data via deep multi-scale learning, Comput. Netw., 162, 106861, https://doi.org/10.1016/j.comnet.2019.106861, 2019. a, b
Zhao, W. and Du, S.: Spectral–spatial feature extraction for hyperspectral image classification: A dimension reduction and deep learning approach, IEEE T. Geosci. Remote, 54, 4544–4554, 2016. a, b
Zhao, Z.-Q., Zheng, P., Xu, S.-T., and Wu, X.: Object detection with deep learning: A review, IEEE T. Neur. Net. Lear., 30, 3212–3232, 2019. a
Zheng, H., Zhou, X., He, J., Yao, X., Cheng, T., Zhu, Y., Cao, W., and Tian, Y.: Early season detection of rice plants using RGB, NIR-GB and multispectral images from unmanned aerial vehicle (UAV), Comput. Electron. Agr., 169, 105223, https://doi.org/10.1016/j.compag.2020.105223, 2020. a, b
Zhong, Z., Li, J., Luo, Z., and Chapman, M.: Spectral–spatial residual network for hyperspectral image classification: A 3-D deep learning framework, IEEE T. Geosci. Remote, 56, 847–858, 2017. a, b
Zhuang, C., Wang, Z., Zhao, H., and Ding, H.: Semantic part segmentation method based 3D object pose estimation with RGB-D images for bin-picking, Robotics and Computer-Integrated Manufacturing, 68, 102086, https://doi.org/10.1016/j.rcim.2020.102086, 2021. a
Zhu, X. X., Tuia, D., Mou, L., Xia, G.-S., Zhang, L., Xu, F., and Fraundorfer, F.: Deep learning in remote sensing: A comprehensive review and list of resources, IEEE Geosci. Remote S., 5, 8–36, 2017. a, b
Zou, X., Cheng, M., Wang, C., Xia, Y., and Li, J.: Tree classification in complex forest point clouds based on deep learning, IEEE Geosci. Remote S., 14, 2360–2364, 2017. a, b
https://ieeexplore.ieee.org/Xplore/home.jsp (last access: 22 May 2022)
https://www.scopus.com/ (last access: 22 May 2022)
https://www.sciencedirect.com/ (last access: 22 May 2022)
http://citeseerx.ist.psu.edu/index;jsessionid=5AC85675CD57D62C040448AA01B687CB (last access: 22 May 2022)
https://link.springer.com/ (last access: 22 May 2022)
- Abstract
- Introduction
- From traditional machine learning methods to deep learning models: analysis of geomatics data
- Results and analysis
- Discussion: challenges, open issues, lesson learnt
- Concluding remarks
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Review statement
- References
- Abstract
- Introduction
- From traditional machine learning methods to deep learning models: analysis of geomatics data
- Results and analysis
- Discussion: challenges, open issues, lesson learnt
- Concluding remarks
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Review statement
- References